
编辑|萝卜皮
几个世纪以来,研究人员一直在寻找连接不同领域知识的方法。随着人工智能的出现,我们现在可以探索跨领域(例如,力学-生物学)或不同领域(例如,失效力学-艺术)的关系。
为了实现这一目标,麻省理工学院(MIT)原子与分子力学实验室(LaboratoryforAtomisticandMolecularMechanics,LAMM)的研究人员使用了经过微调的大型语言模型(LLM),来获取多尺度材料失效的知识子集。
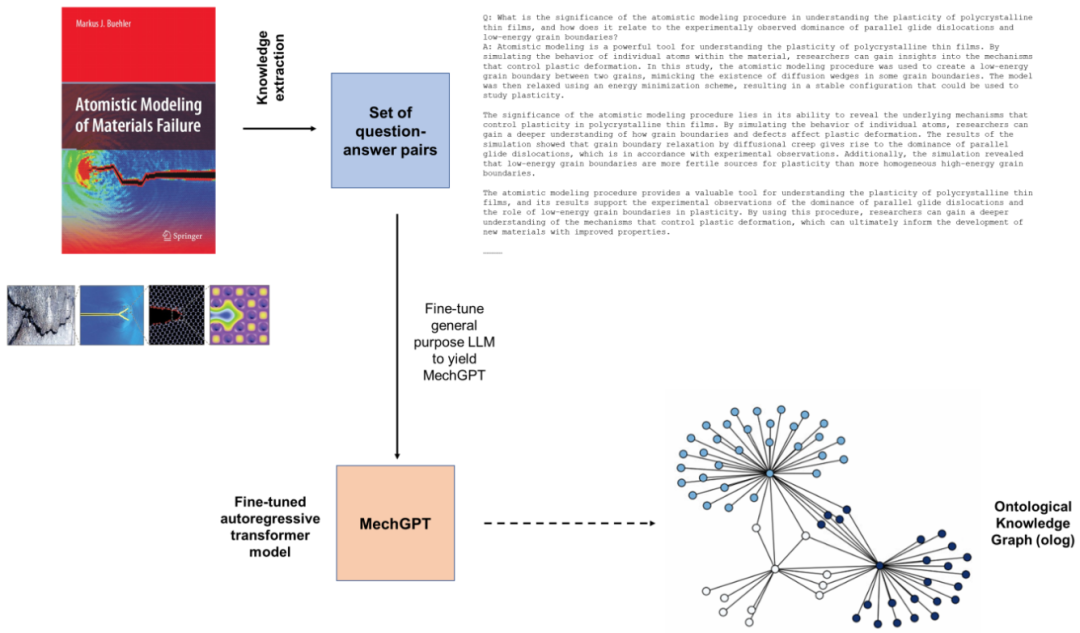
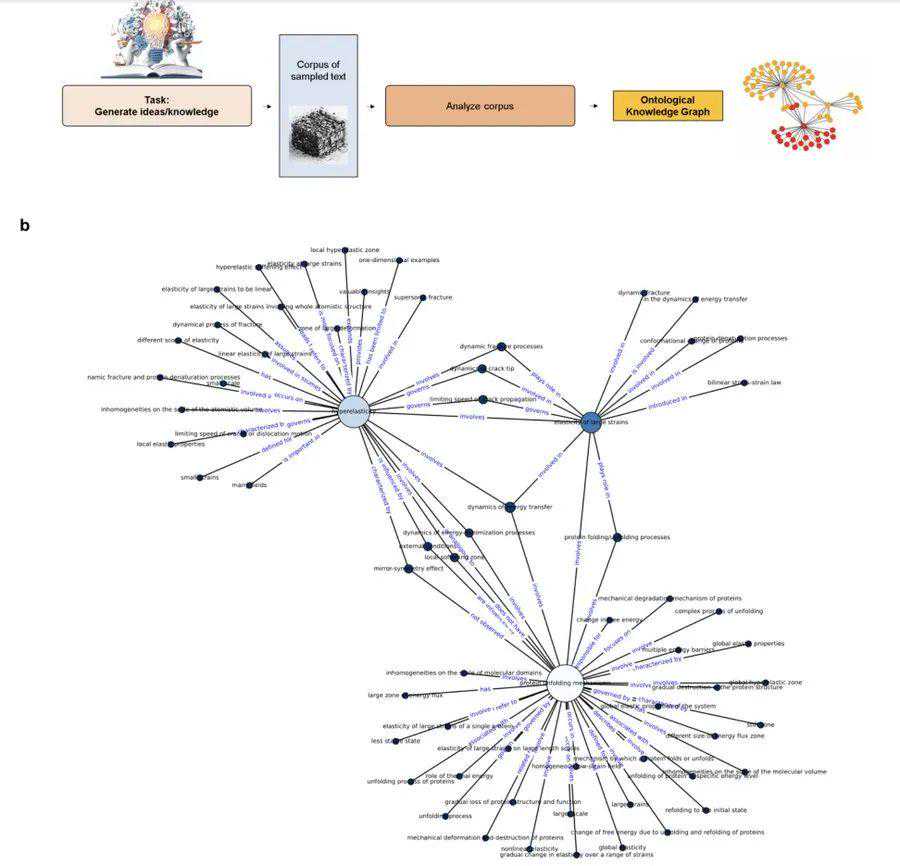
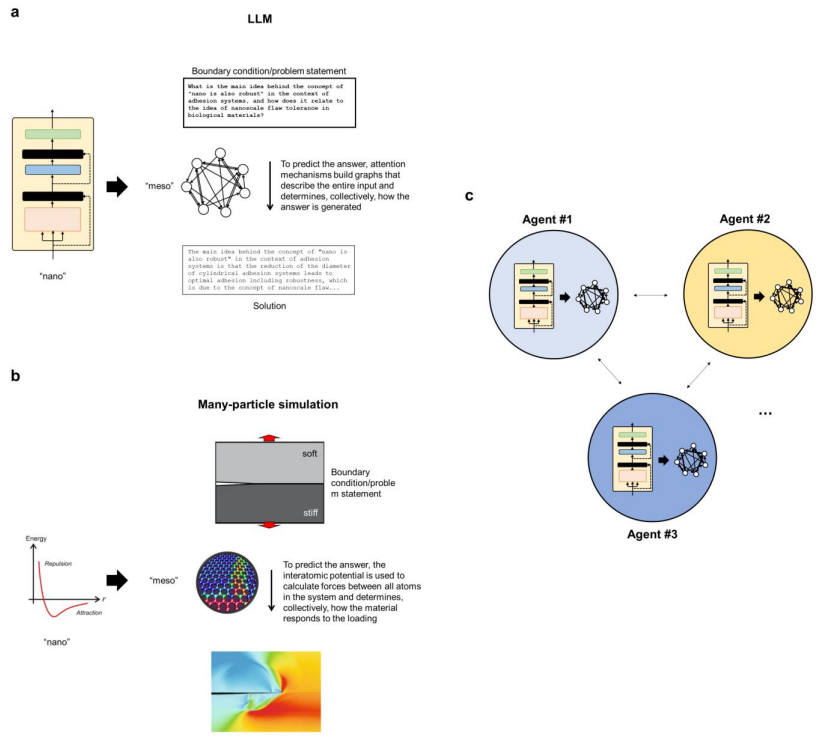
尽管该模型具有一定的能力来回忆训练中的知识,但研究人员发现LLM对于通过本体知识图提取结构见解更加有意义。这些可解释的图形结构提供了解释性见解、新研究问题的框架以及知识的视觉表示,这些知识也可用于检索增强生成。
该研究以「MechGPT,aLanguage-BasedStrategyforMechanicsandMaterialsModelingThatConnectsKnowledgeAcrossScales,DisciplinesandModalities」为题,于2023年10月19日发布在《AppliedMechanicsReviews》。

现在,大型语言模型(LLM)的出现挑战了科学探究的范式,不仅带来了基于人工智能/机器学习的新建模策略,而且还带来了跨领域连接知识、想法和概念的机会。这些模型可以补充传统的多尺度建模,用于分层材料的分析和设计以及力学中的许多其他应用。
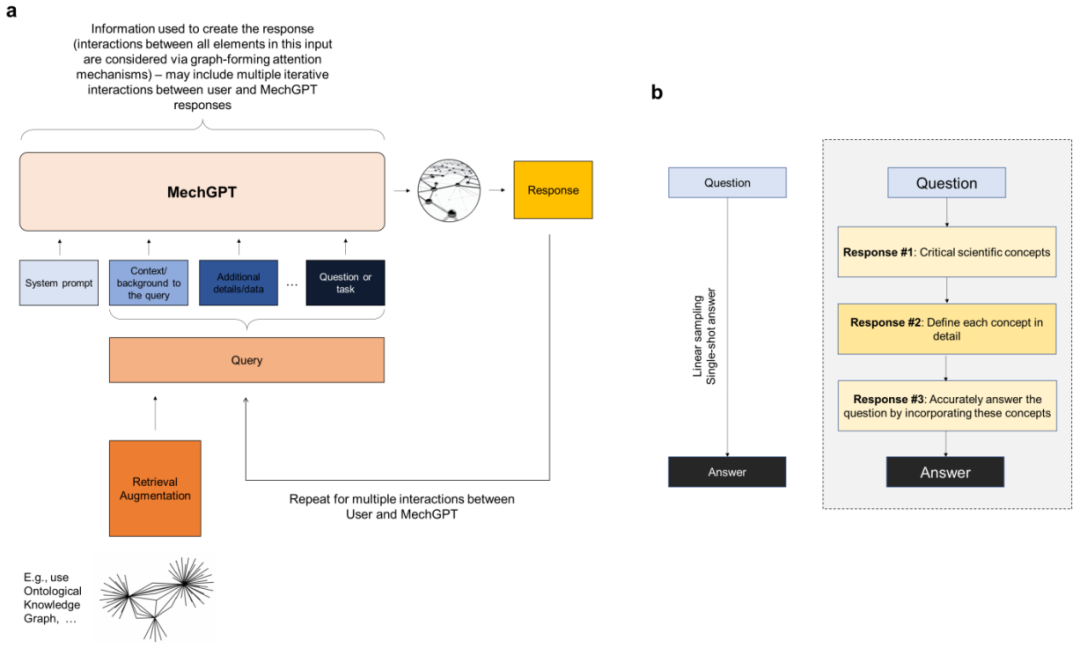
在这里,LAMM的研究人员以最近提出的LLM在力学和材料研究和开发中的用途为基础,并且基于Llama-2basedOpenOrca-Platypus2-13B的通用LLM,开发了一个经过微调的MechGPT模型,该模型专注于模型材料失效、多尺度建模以及相关学科。
选择OpenOrca-Platypus2-13B模型是因为其在推理、逻辑、数学/科学和其他学科等关键任务上具有高水平的性能,能够以可管理的模型大小提供跨学科的广泛的、可转移的知识和通用概念,并提供计算效率。
LLM在科学领域有着强大的应用。除了能够分析大量数据和复杂系统之外,在力学和材料科学领域,LLM用于模拟和预测材料在不同条件下的行为,例如机械应力、温度和化学相互作用等。正如早期工作所示,通过在分子动力学模拟的大型数据集上训练LLM,研究人员可以开发能够预测新情况下材料行为的模型,从而加速发现过程并减少实验测试的需要。
此类模型对于分析书籍和出版物等科学文本也非常有效,使研究人员能够从大量数据中快速提取关键信息和见解。这可以帮助科学家识别趋势、模式以及不同概念和想法之间的关系,并为进一步研究产生新的假设和想法。
在这里,该团队将重点放在后者的开发上,并探索MechGPT的使用,这是基于Transformer的LLM系列中的一种生成人工智能工具,专门针对材料失效和相关的多尺度方法进行了训练,从而评估这些策略的潜力。
该研究提出的策略包括几个步骤,包括首先是蒸馏步骤,其中研究人员使用LLM从原始数据块(例如从一个或多个PDF文件中提取的文本)中生成问答对,然后在第二步中利用这些数据来微调模型。这里探索的初始MechGPT模型在材料失效的原子建模领域进行了专门训练,并证明了其在知识检索、通用语言任务、假设生成等方面的有用性。
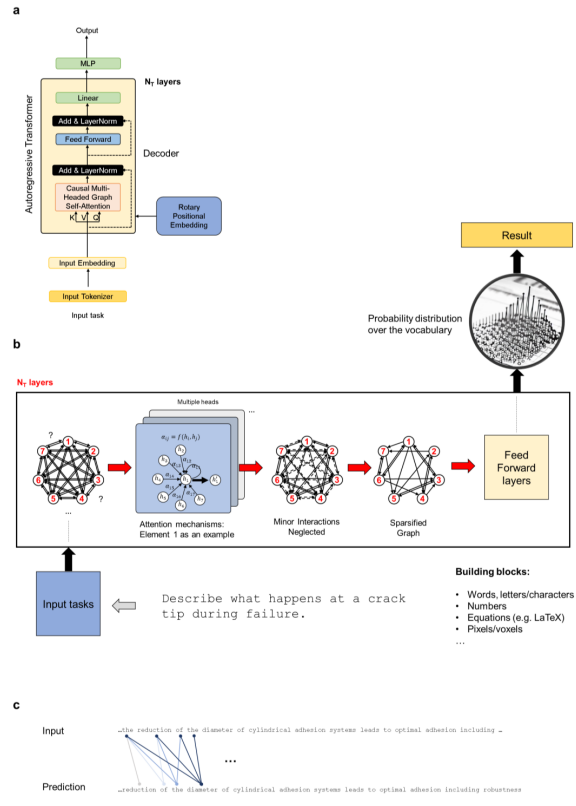
论文里,研究人员介绍了总体建模策略,使用特定语言建模策略生成数据集以从源中提取知识,然后使用新颖的力学和材料数据集训练模型。研究人员分析讨论了MechGPT的三个版本,其参数大小从130亿到700亿不等,上下文长度达到超过10,000个token。
同时,该团队进一步提供了不同抽象级别的语言模型和多粒子系统之间的概念比较,并解释了如何将新框架视为提取管理复杂系统的普遍关系的手段。
总体而言,该研究提出的工作有助于开发更强大、更通用的人工智能模型,这些模型可以帮助推进科学研究并解决特定应用领域的复杂问题,从而可以深入评估模型的性能。与所有模型一样,它们必须经过仔细验证,它们的有用性存在于所提出的问题的背景、其优点和缺点以及帮助科学家推进科学和工程的更广泛的工具中。
而且,作为科学探究的工具,它们必须被视为理解、建模和设计我们周围世界的工具集合。随着人工智能工具的快速发展,它们在科学背景下的应用才刚刚开始带来新的机遇。
相关报道:

-

新车 | 售约58万元起/3.3秒“破百”,凯迪拉克IQ锐歌-V官图发布
2026-01-22 -
 2025-12-02
2025-12-02 -

柳州体育中心内场全封闭升级改造 23年来最彻底的整修 你常去吗?
2025-07-17 -
 2025-04-13
2025-04-13
-
如果王室继承看颜值,他当王储毫无悬念?
2025-10-01 -
旧宫新语丨贾薇:情笃难寄——紫禁城西六宫女性空间的私密祭奠、信仰及其陈设
2025-10-18 -
2015年智能硬件最具潜力产品大盘点
2025-07-15 -
提升明显的音响方案成都丰田雷凌音响改装升级
2024-12-01