介绍一下我们在3D表征学习上的新工作,ReCon:ContrastwithReconstruct,通过生成式学习指导对比学习实现高效的3D表征,在ScanObjectNN上实现91.26%的OA,以及多项SOTA,代码已开源。

我们知道,3D点云长期遭受着严重的数据缺乏问题,常用的ModelNet40、ShapeNet数据集仅包含14k与51k的数据,这与2D或图文多模态上动辄14M、300M甚至5B的超大规模数据形成巨大对比。因此,如何在有限的数据上高效的提取3D表征成为我们的研究动机,我们从Generative和Contrastive两大主流的自监督框架入手进行分析。
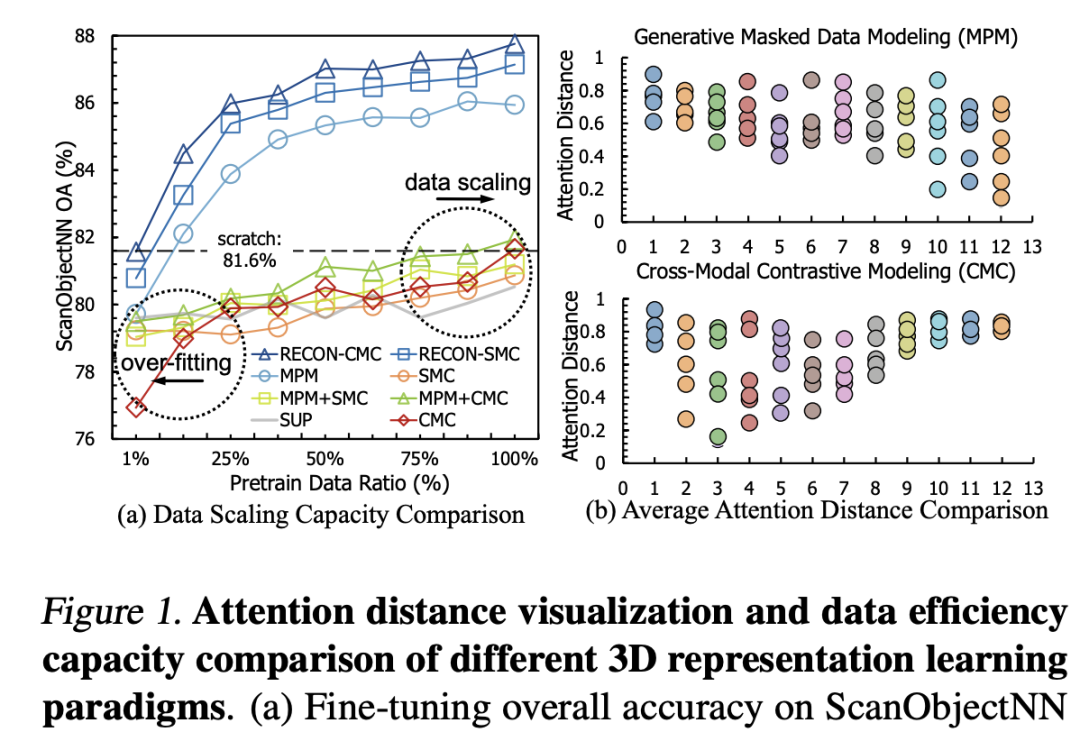
我们首先研究了MPM(MaskedPointModeling)、CMC(Cross-modalContrastive)和SMC(Single-modalContrastive)等预训练方法对Pretrain数据的依赖性,我们在ShapeNet上进行预训练,并在ScanObjectNN上测试迁移性能,结果在图(a)中展示。我们发现:
Contrastive方法具有Over-fitting问题
当缺乏预训练数据(90%)时,Contrastive模型无法带来泛化性能,而Generative模型仅需大约25%的数据就可以给下游任务带来显著的性能提升。这表明,对比学习很容易找到表征捷径来过度拟合有限的数据[1],而生成式模型对数据的依赖程度较低,可以用很少的数据学习到良好的初始化。
Generative方法具有Datafilling问题
当预训练数据扩大时,对比学习呈现出更好的潜在能力,而生成模型在提供更多数据时只带来较小的性能提升(从75%提升到100%的数据对下游任务的改善并不明显)。这表明,当预训练数据足够时,对比学习可以为生成模型带来更强的数据扩展能力。在2D中,对比学习模型[2]在下游任务的效果超越了扩展能力较弱的生成模型[3]。
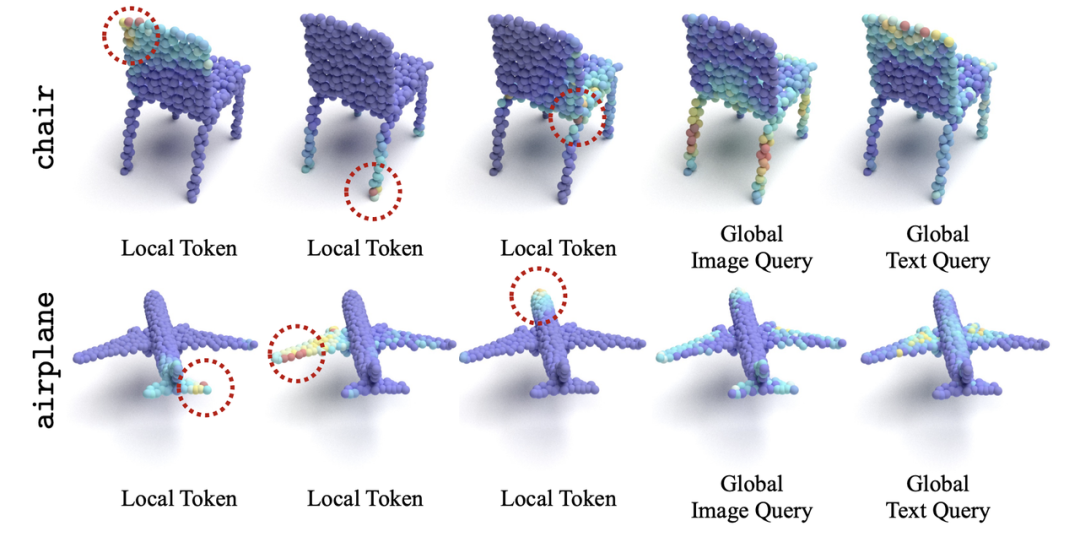
我们还研究了MPM(MaskedPointModeling)、CMC(Cross-modalContrastive)在感受野和注意力区域上的区别,类比2D中ViT的AverageAttentionDistance[4],我们根据3Dpatch中心之间的欧式距离和attentionmap权重来生成3DAverageAttentionDistance,结果在图(b)中展示。我们观察到一个模式差异问题,即对比模型的注意力主要集中在全局领域,其注意力距离逐步上升并趋于一个较高值,而生成模型对集中的局部注意力有兴趣,这与Xie等人在2D的观察结果一致[5]。
如何有效地结合Contrastive和Generative方法,并且规避其在注意力模式上的区别成为我们工作的motivation。
二、知识蒸馏——对比式和生成式的统一理论
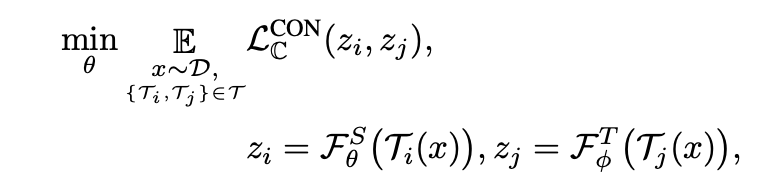
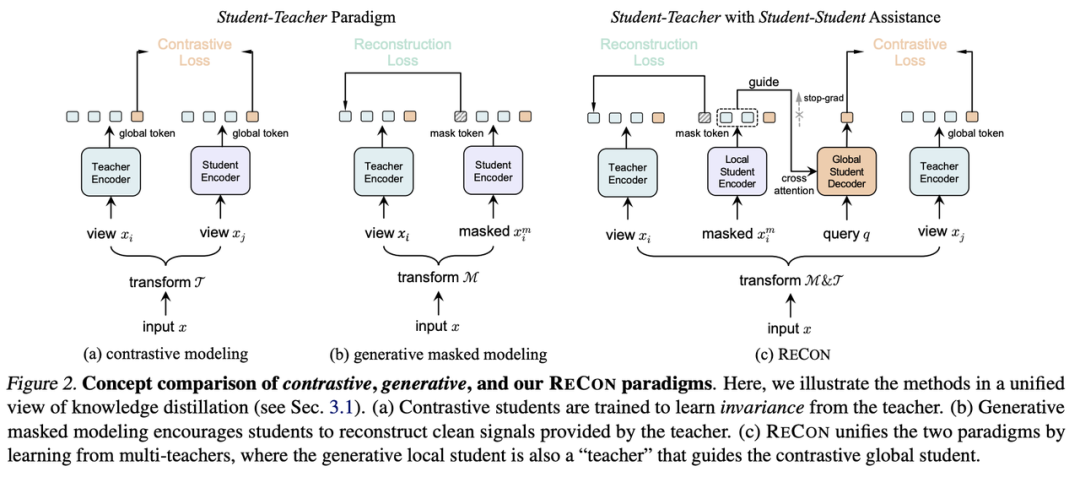
对比学习通过对统一样本数据的不同view进行拉进、不同样本的view进行推远来促使模型学习深层次的知识,这里的view可以是单模态[6],也可以是多模态的[7],其本质上相当于在featuremap或logits上相互提供监督信号来寻找全局语义上的联系,即不同view下特征的蒸馏。
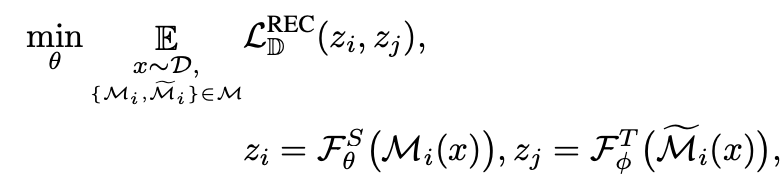
生成式模型通过denoisingautoencoder的方式,对数据样本施加扰动(例如mask),并设置数据样本的某一种view(例如pixel[3]、VQcode[8]、HOG特征[9]等等)作为teacher提供监督信号。其本质在于迫使模型学习局部特征的相互关系来实现对教师特征的对齐。
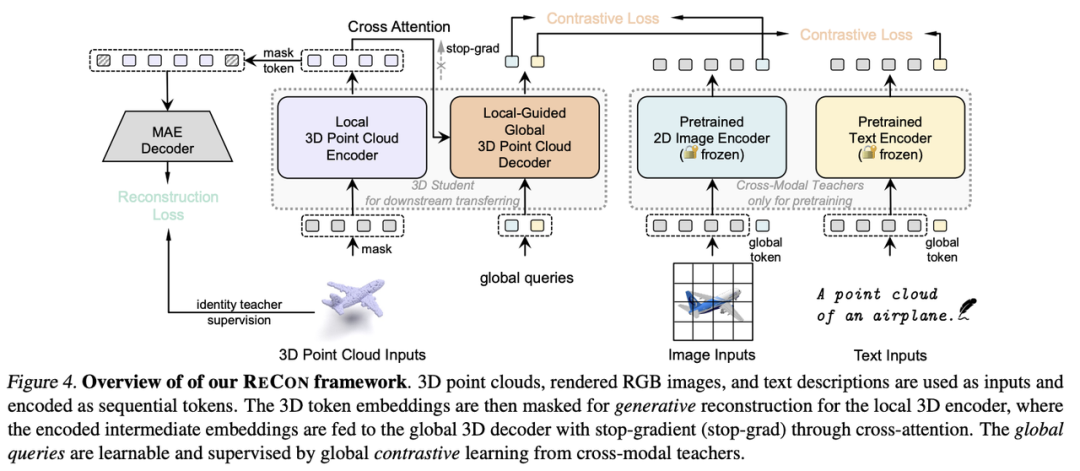
在知识蒸馏的视角下,我们统一了Contrastive和Generative两种自监督范式,由此引申出ReCon模型,通过多教师蒸馏与学生协同学习下的自监督模型(student-teacherknowledgedistillationwithstudent-studentassistance)。Localteacher通过局部语义的复原来使Localstudent学到丰富的局部知识,Localstudent向Globalstudent提供局部知识以帮助其全局知识的学习。
在细节上,二者使用不同的TransformerAttention架构来规避注意力模式的差异。关于生成式学习的形式,可以类似于BEiT[8]、ACT[10]通过Tokenizer生成语义token用于重建,即使用Tokenizer作为Teacher监督,也可以类似于MAE[3]、PointMAE[11]直接重建源数据,即使用Identity作为Teacher监督。而关于对比学习的形式,可以类似于CLIP[7]进行跨模态之间的对比学习,也可以类似于SimCLR[6]、PointContrast[12]进行单模态的对比学习。
三、方法
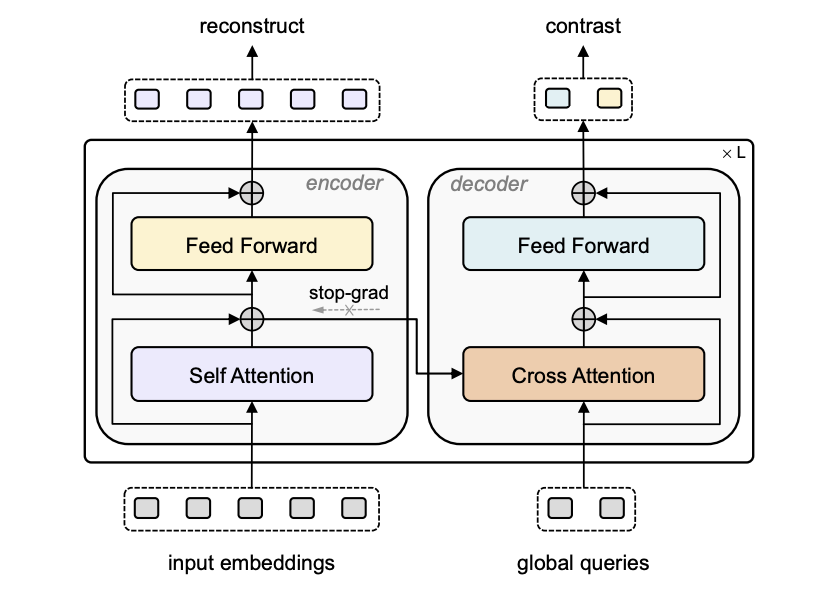
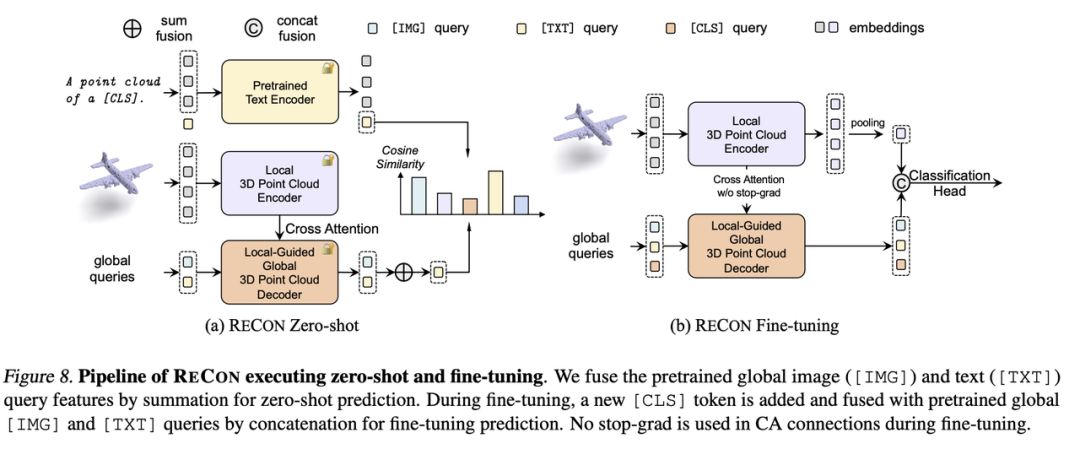
我们在主图展示了ReCon的encoder-decoder框架,其中PointIdentity作为Local3DPointCloudEncoder教师,跨模态预训练模型作为Global3DPointCloudDecoder教师,这种配置在后续的消融实验被验证有最优的效果。我们使用timm[13]或CLIP[7]的视觉编码器作为ReCon的2DTeacher,CLIP的文本编码器作为ReCon的TextTeacher,并在后续的消融实验发现freezeparameter有利于知识的迁移。对于Local3DPointCloudEncoder,我们完全采用MAE式的非对称结构,来防止位置编码在点云重建中可能附有的知识泄露。
在模型结构上,我们使用了类似BART[14]的encoder-decoder结构,每个Stream在一个layer中均包含一个Attention层与FFN层,其中encoder的inputsembeding产生CrossAttention的K与V,并使用stop-grad来防止梯度干扰。由于globalqueries一般仅包含少量的几个token,在运算效率上并不会比单流网络增加很多。
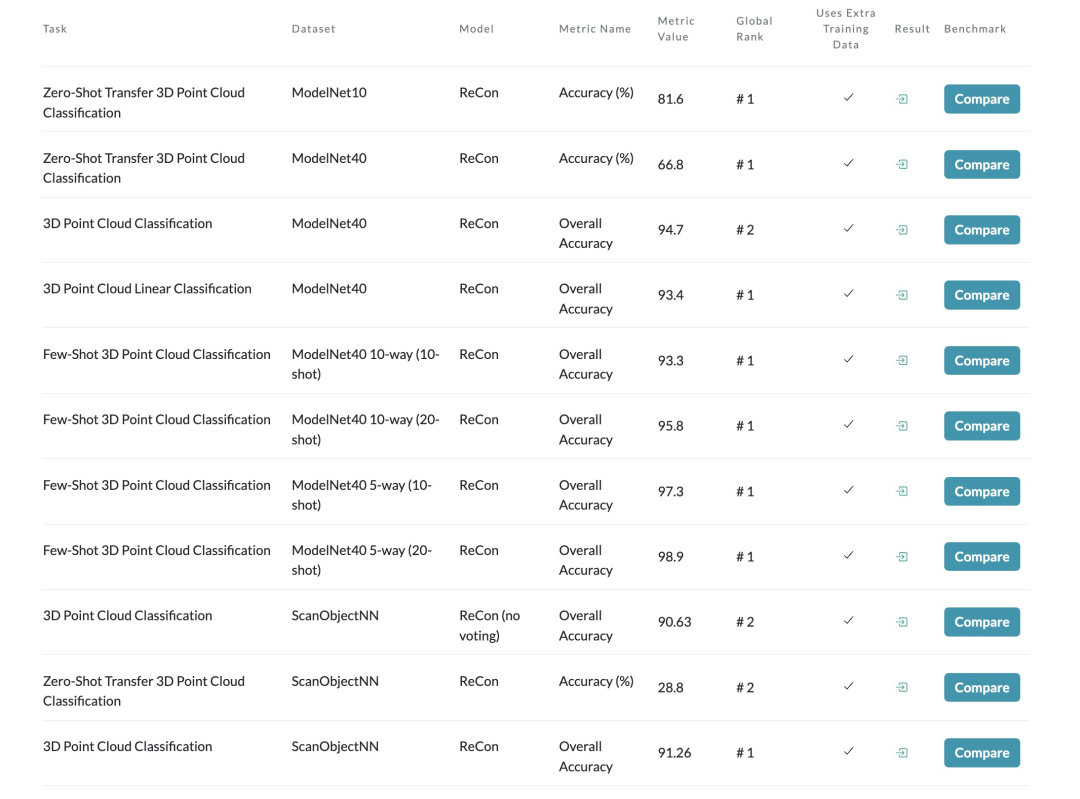
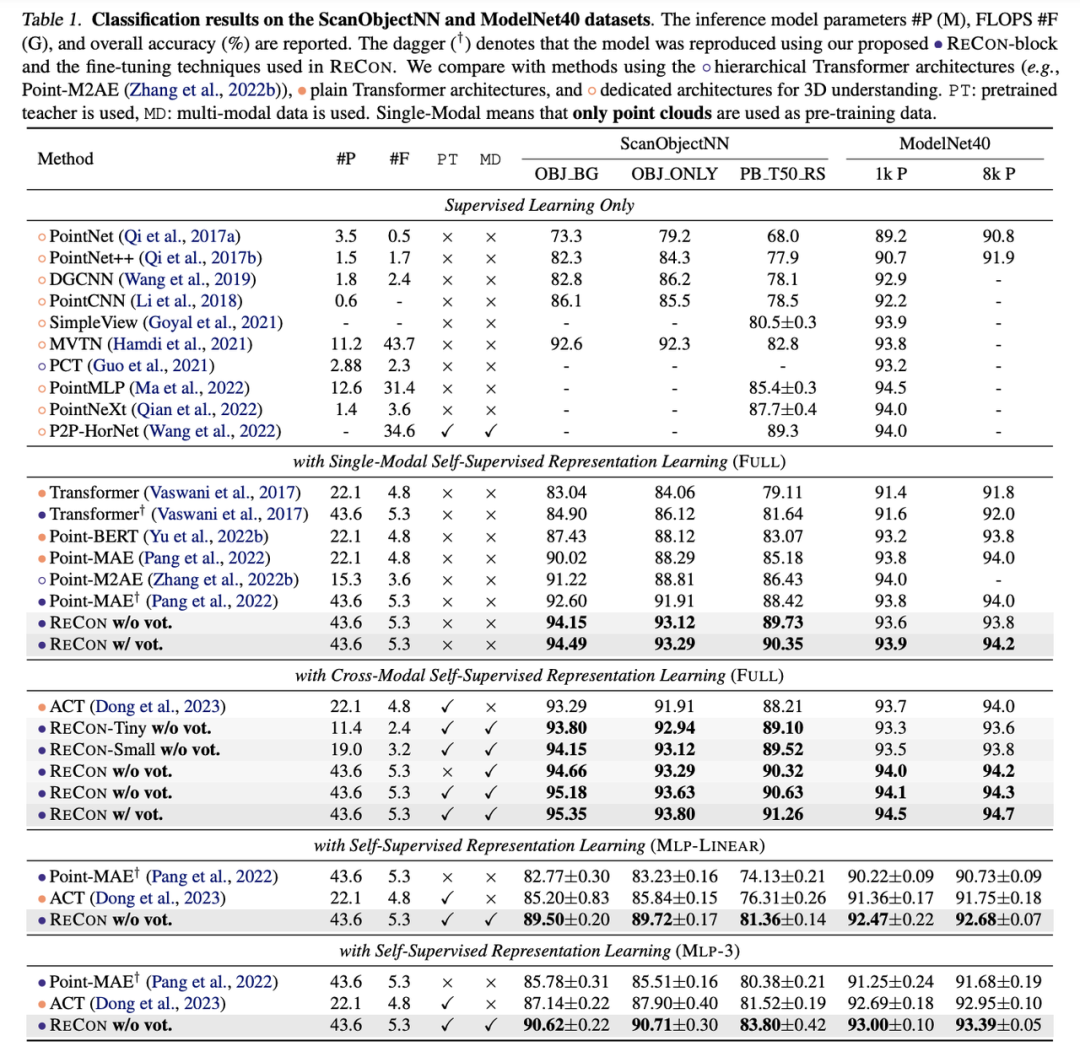
四、实验我们的ReCon在点云分类最常用的两个数据集ScanObjectNN和ModelNet40均取得了SOTA的性能,尤其是在ScanObjectNN的迁移效果,达到了惊人的91.26%OverallAccuracy。
此外,我们将ReCon分为三种设置,ReCon-T、ReCon-S和ReCon,他们的模型结构完全一样,仅有模型维度上的区别。即使使用了更小维度的ReCon依然产生了优异的性能,拥有19M甚至11M参数的ReCon依然大幅度优于PointMAE等3D自监督方法。

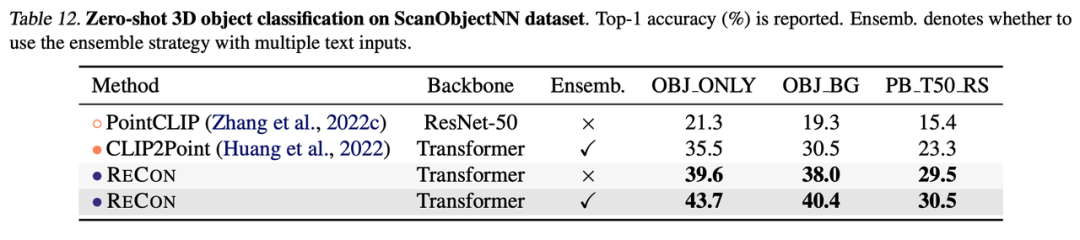
如果进一步利用PretrainTextTeacher,可以实现Zero-Shot分类,下表展示了ReCon在ModelNet40和ScanObjectNN的testset上的Zero-Shot性能,同样远超其他方法。
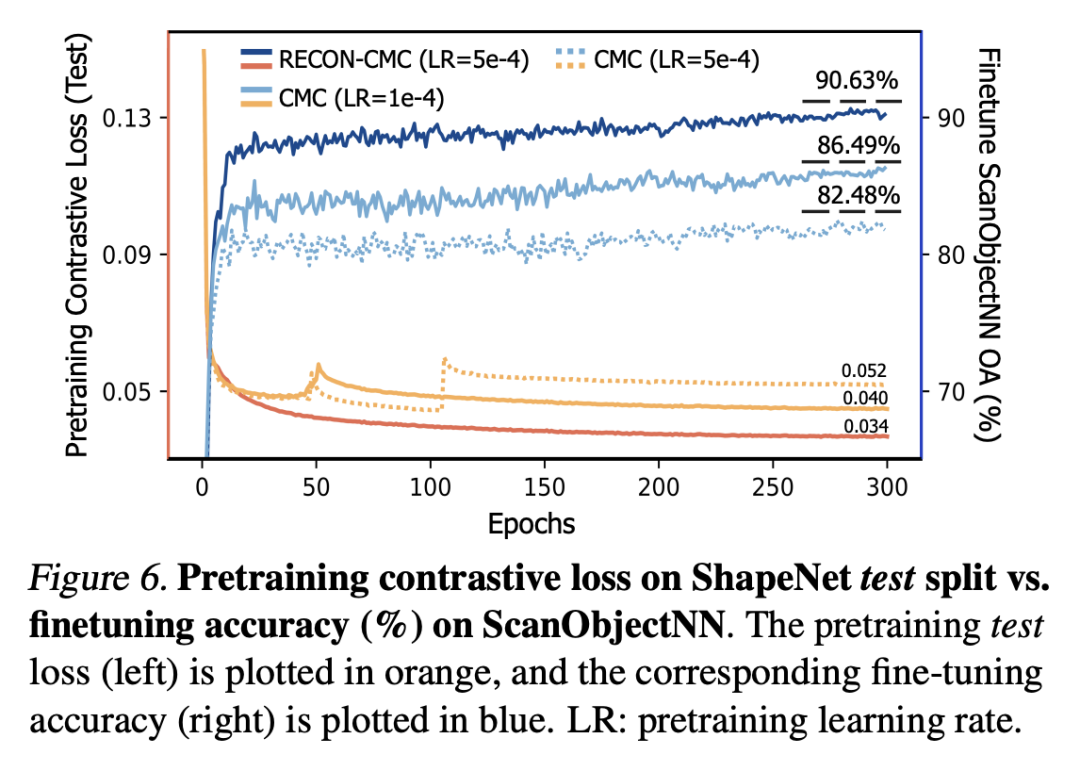
我们首先从loss的角度进行分析,我们记录了vanillaCMC(Cross-ModalContrastive)与我们的经过重建指导的ReCon-CMC在ShapeNet测试集(未用于预训练)的loss曲线,并记录了在ScanObjectNN上的相应微调精度。可以看出,我们的ReCon-CMC的测试对比损失始终低于普通的CMC,并且更加稳定地收敛到较低的值,表明我们的ReCon带来了更好的预训练对比任务的泛化性能,而不会陷入简单解决方案的捷径,预训练过程中的过拟合问题得到缓解。
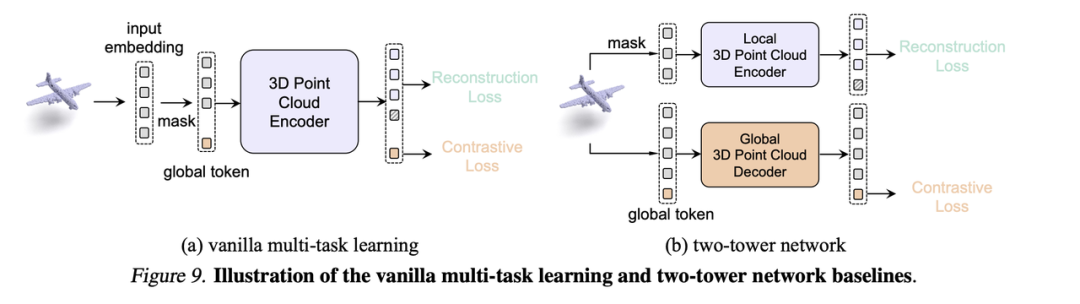
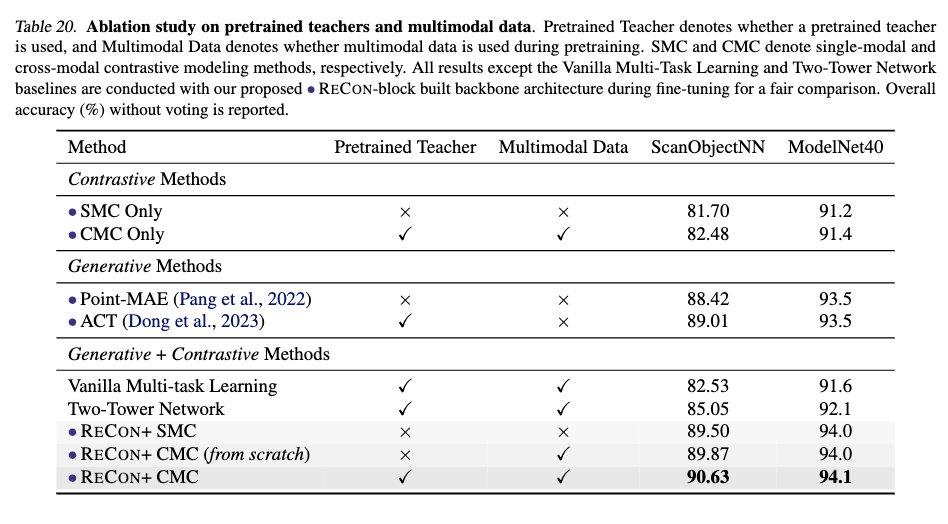
为验证模型的收益并不来自教师,而是因为ReCon结构是一种优良的Generativelearning和Contrastivelearning结合方法,我们在论文的附录C中探究了另外两种掩码数据建模和对比学习结合的方法,包括VanillaMulti-taskLearningFusion和Two-TowerNetwork,他们都用了包含预训练权重的跨模态教师来做指导。
vanillamulti-task通过添加多个类似于[cls]Token的()token用于进行对比学习
two-towernetwork通过两个单独的Transformer训练各自的代理任务
经过实验,简单的将包含预训练权重的跨模态知识进行传递并不会产生效果,我们猜测这是引言所表现出的模式差异所导致的,即Local-Global的注意力模式差异与数据缺乏导致的过拟合问题。而这种模式差异正是我们设计ReConblock的动机。

ReCon大幅提升了3D表征学习的效果,在点云分类与Zero-Shot中均取得了SOTA的性能。但我们认为ReCon发现并解决的问题并不是在3D中特有的,在其他缺乏数据,或相对缺乏数据的模态中依然有可能有效,我们希望有更多ReCon-Style的架构在更多领域出现。
七、相关工作AutoencodersasCross-ModalTeachers:CanPretrained2DImageTransformersHelp3DRepresentationLearning?ICLR’23
CLIP-FO3D:LearningFreeOpen-world3DSceneRepresentationsfrom2DDenseCLIP
参考文献:[1]Shortcutlearningindeepneuralnetworks
[2]CLIPItselfisaStrongFine-tuner:%%Top-1AccuracywithViT-BandViT-LonImageNet
[3]Maskedautoencodersarescalablevisionlearners
[4]Animageisworth16x16words:Transformersforimagerecognitionatscale
[5]Revealingthedarksecretsofmaskedimagemodeling
[6]Asimpleframeworkforcontrastivelearningofvisualrepresentations
[7]Learningtransferablevisualmodelsfromnaturallanguagesupervision
[8]Beit:Bertpre-trainingofimagetransformers
[9]Maskedfeaturepredictionforself-supervisedvisualpre-training
[10]AutoencodersasCross-ModalTeachers:CanPretrained2DImageTransformersHelp3DRepresentationLearning?
[11]Maskedautoencodersforpointcloudself-supervisedlearning
[12]Pointcontrast:Unsupervisedpre-trainingfor3dpointcloudunderstanding
[13]PyTorchImageModels
[14]Bart:Denoisingsequence-to-sequencepre-trainingfornaturallanguagegeneration,translation,andcomprehension
IllustrationbyIconScoutStorefromIconScout
-The-

扫码观看!
本周上新!
“AI技术流”原创投稿计划
投稿内容
//最新技术解读/系统性知识分享//
//前沿资讯解说/心得经历讲述//
投稿须知
稿件需要为原创文章,并标明作者信息。
我们会选择部分在深度技术解析及科研心得方向,对用户启发更大的文章,做原创性内容奖励
投稿方式
发送邮件到
chenhongyuan@
添加小编微信!
关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门技术社群以及。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”:
⤵一键送你进入TechBeat快乐星球

-
 2025-01-12
2025-01-12 -
 2025-01-21
2025-01-21 -
 2024-11-19
2024-11-19 -
 2025-07-13
2025-07-13
-
汽车音响十大品牌排名,汽车音响哪个牌子的好
2024-12-15 -
韩国祭出大杀器 超5000元银砖机 比iphone7风骚太多
2025-03-29 -
荣耀Magic Book X 14 体验分享:入门级轻薄本也有生产力?
2025-03-26 -
新车 |“轩逸两厢版”,日产Note Aura Nismo曝光,售价约人民币17万
2025-03-30