ShapeLLM:Universal3DObjectUnderstandingforEmbodiedInteraction
标题:ShapeLLM:基于实体交互的通用3D对象理解
地址:
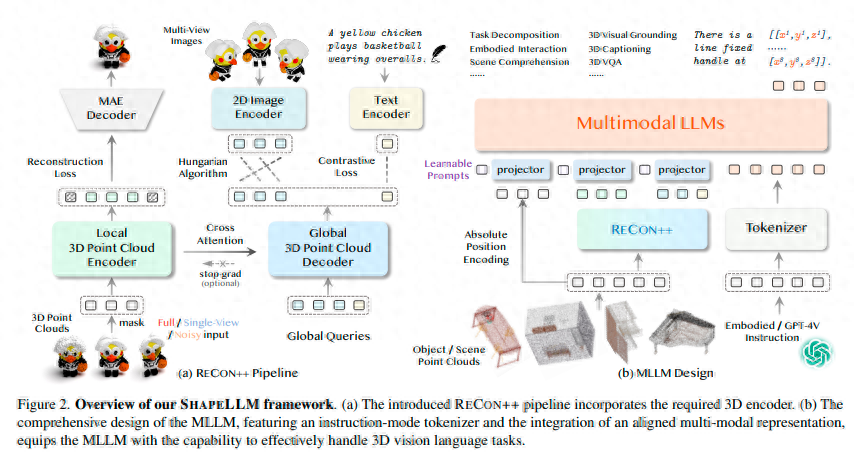
摘要:本文介绍了SHAPELLM,这是首个专为实体交互而设计的3D多模态大型语言模型(LLM),探索了利用3D点云和语言进行通用的3D对象理解。SHAPELLM基于一个改进的3D编码器构建,通过将RECON[129]扩展到RECON++,利用多视角图像蒸馏来增强几何理解。通过将RECON++作为3D点云输入编码器用于LLM,SHAPELLM在构建的指令跟随数据上进行训练,并在我们新设计的人工筛选评估基准3DMM-Vet上进行测试。RECON++和SHAPELLM在3D几何理解和语言统一的3D交互任务方面取得了最先进的性能,例如实体视觉定位。
解决的问题:
该论文主要解决的问题是探索和开发一个针对3D对象理解的通用模型,即3D多模态大语言模型(LLM)。这个模型被命名为SHAPELLM,旨在通过结合3D点云和语言信息,实现对3D对象的深入理解。论文的作者在构建SHAPELLM时,对原有的3D编码器RECON进行了改进,提出了RECON++,通过多视图图像蒸馏来增强对几何结构的理解。
此外,论文还提出了一个新的人为策划的评估基准,即3DMM-Vet,用于评估模型在3D几何理解和语言统一的3D交互任务中的性能。实验结果显示,SHAPELLM和RECON++在3D几何理解和语言统一的3D交互任务中实现了最先进的性能,如具身视觉定位等。
因此,该论文解决的问题主要集中在如何结合3D点云和语言信息,提高对3D对象的理解能力,并开发相应的评估基准来评估这种理解能力的性能。
创新点:
3D多模态大型语言模型(SHAPELLM):论文提出了一种名为SHAPELLM的3D多模态大型语言模型,该模型具有通用化的识别和具身交互理解能力。这种模型能够处理3D点云数据,为机器人或其他具身智能体提供更为丰富的交互方式。
多视图蒸馏技术:传统的3D点云编码通常只考虑单一视图的信息,但论文提出了一种名为RECON++的新型3D点云编码器,它通过多视图蒸馏技术,利用多视图之间的互补性来提取更为丰富的特征信息。这种技术可以有效地提高模型的识别和理解能力。
3D视觉指令调优:论文提出了一种在构建的指令遵循数据上对3D视觉指令进行调优的方法。这种方法使得模型能够更好地理解和执行具身交互任务,提高了模型的泛化能力。
3D评估基准(3DMM-Vet):为了评估模型的具身交互能力,论文建立了一个名为3DMM-Vet的3D评估基准。这个基准包含四个级别的评估任务,从基本的感知到控制语句生成,为模型的性能提供了全面的评价。
对单视图点云输入的鲁棒性研究:论文还研究了模型对单视图点云输入的鲁棒性。实验结果表明,SHAPELLM在处理被遮挡或不完全的点云数据时,仍表现出强大的鲁棒性,这为模型在实际场景中的应用提供了可能。
系统架构:
结果:

结论:
本文介绍了SHAPELLM,一种用于实体交互的3D多模态LLM,能够进行通用识别和实体交互理解。我们首先提出了一种新颖的3D点云编码器RECON++,通过利用多视角蒸馏和扩展3D表示学习,作为SHAPELLM的基础3D表示编码器。然后,我们针对构建的指令跟随数据进行了3D视觉指令调优,以实现通用和实体理解。我们还建立了一个3D评估基准,称为3DMM-Vet,用于评估在实体交互场景中的四个级别的能力,从基本感知到控制语句生成。
实际应用价值:
提升3D物体识别准确率:论文中提出的RECON++3D编码器在ScanObjectNN和ModelNet40等3D物体识别任务上取得了新的最佳表现,其准确率分别达到了95.25%和95.0%,超过了之前的最佳记录。这一成果对于需要高精度3D物体识别的应用场景,如自动驾驶、机器人导航、增强现实等,具有重要的实际应用价值。
统一处理多种下游任务:论文中提出的SHAPELLM框架成功地将多种下游任务统一到一个模型中,包括3D标题生成、3D视觉问答、具身任务规划与分解、3D具身视觉定位以及3D精确引用对话等。这一特性使得该框架可以广泛应用于各种需要处理3D数据的场景,如虚拟现实、游戏设计、电子商务等。
推动相关领域研究:论文中提出的SHAPELLM框架和3DMM-Vet基准测试集为未来的研究提供了新的方向和挑战。随着相关研究的深入,我们可以期待在3D物体识别、3D数据理解以及具身交互等领域取得更多的突破和进步。
促进技术发展与社会应用:该论文的研究成果有助于推动人工智能、计算机视觉、自然语言处理等领域的技术发展,进而促进这些技术在社会各个领域的应用。例如,通过提高3D物体识别的准确率,我们可以开发出更智能的机器人助手,帮助人们完成各种复杂任务;通过统一处理多种下游任务,我们可以构建更丰富的虚拟现实世界,提供更沉浸式的用户体验。

-
 2025-02-21
2025-02-21 -
 2024-12-04
2024-12-04 -

波兰Muarah Audio产品线详解:黑胶唱盘+电子管唱放+功放+专利速控
2025-01-12 -
 2025-07-13
2025-07-13
-
Pierre Braunstein教授成为全球科技创新论坛创始人
2025-05-08 -
Partyhouse派对屋保护消费者合法权益,不止315!
2025-03-12 -
总价超1500万!中国市场上的5款超豪华SUV赏析
2025-01-20 -
买庆铃卡车当私家车用,稍加改装,大哥让双排座轻卡回归当年风采
2025-12-12