(报告出品方:国盛证券)
一、光通信-AI算网融合下的传输最优解之一1.1光通信产业链
光通信产业链涵盖多个环节,上游芯片厂商和下游客户较为强势。简单来看光通信产业分为上中下游,上游主要是核心零部件环节包括光芯片、光学元件、电芯片,中游可以分为光器件、光模块,下游按照应用场景可以分为电信市场和数通市场,整条光通信产业链较为复杂,话语权较强的集中在上游和下游两端,因此对于光模块厂商而言成本控制能力至关重要,决定了公司的整体盈利能力。
上游零部件:光芯片:有源光芯片(激光器芯片、探测器芯片等)、无源光芯片(波分复用、光耦合器等);主要厂商:源杰科技、仕佳光子、光迅科技、长光华芯、华工科技、海信宽带、武汉光安伦、华为海思、中兴通讯、Lumentum、Finisar、Avago、AAOI、II-VI、Ociaro、Acacia、三菱、住友、博通等。光学元件:平面/球面光学元件、横压玻璃非球面透镜等;主要厂商:天孚通信、太辰光、腾景科技、光库科技、中瓷电子、博创科技、昂纳技术等。电芯片:电芯片目前仍以海外进口为主,包括LDdriver、TIA、LA、CDR、DSP等;主要厂商:Marvell、博通、Credo、超燃半导体、华为海思、傲科光电等。
中游器件模块:光器件:有源光器件-激光器(DFB/FP/VCSEL)、探测器(PIN/APD)、光放大器、光调制器(DML/EML)、光收发次模块(TOSA/ROSA/BOSA)等;无缘光器件-光隔离器、光分离器、光开关、光纤连接器、波分复用解复用器、光分路器、光衰减器、FA光线阵列、光耦合器等;主要厂商:光迅科技、博创科技、华工科技、Lumentum、Finisar、AAOI、II-VI等。光模块:数通光模块、电信光模块,100/200/400/800G/1.6T等;主要厂家:中际旭创、新易盛、光迅科技、华工科技、博创科技、联特科技、剑桥科技、Lumentum、Finisar、Avago、AAOI等。
下游应用:电信市场:通信设备厂如华为,中兴,烽火,瑞斯康达、格林伟迪、剑桥科技、Nokia、Cisco等;终端电信运营商如三大运营商、中国广电、Verizon、TT、沃达丰、软银等。数据中心市场:云厂商如阿里云、腾讯云、华为云、百度云、AWS、Microsoft、Google、Meta等。
1.2网络架构分析以及对应光通信网络
光通信与网络架构密切相关,网络架构的持续演进和多样性对光通信提出一系列特定的需求。网络架构是指网络系统中各个组件和子系统之间的结构和组织方式,决定了数据在网络中的传输方式、管理方式以及网络整体的性能和可靠性,网络架构包括硬件和软件两个方面。不同的网络架构对光通信具备不同的需求,包括传输速率、带宽要求、传输距离、技术标准、通信协议、部署环境等。
1.2.1以太网VSIB,兼容性与高性能之争
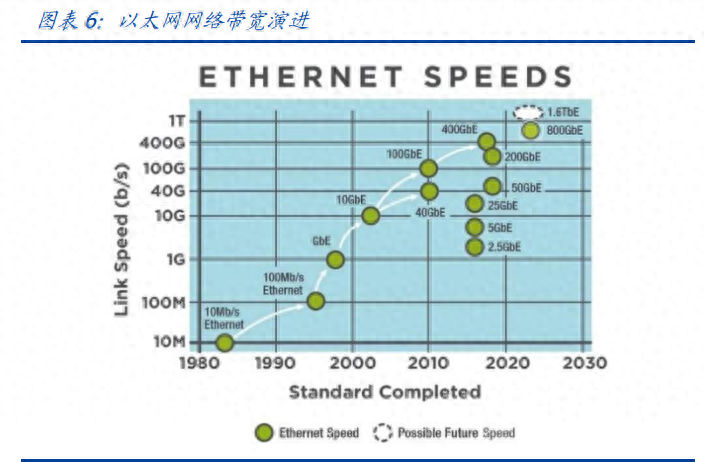
以太网(Ethernet)是当前广泛应用的局域网,基于IEEE组织802.3网络标准,使用标准的以太网设备、线缆和接口卡,借助交换机或路由器实现各个网络节点之间的通信。以太网最初由Xerox、Intel、DEC公司联合开发,并于1980年发布首个以太网标准,即10Mbps基带局域网;后来标准逐步完善,推出了多个传输速率,目前具备标准以太网(10Mbit/s)、快速以太网(100Mbit/s)、千兆以太网(1000Mbit/s)和万兆以太网(10Gbit/s)等。以太网通常采用总线架构,广泛支持家庭和办公室网络、5G承载、云计算、智慧城市和数据中心等多种应用场景。
InfiniBand(IB)具有高带宽、低时延、高可靠性和高可扩展性,适用于高性能计算和人工智能等领域,如超级计算机、GPU服务器、大数据分析等。IB网络带宽从SDR、DDR、QDR、FDR、EDR、HDR到NDR不断发展,提供多个传输速率的选择,InfiniBand通过专用设备、线缆和接口卡,以交换机实现直接连接和高效通信。IB网络由InfiniBandTradeAssociation(IBTA)定义,技术在超级计算机集群和GPU服务器等领域广泛应用,采用先进的分布式网络架构,显著提升性能,支持更高的传输速率和更大的带宽,尤其适用于科学计算和大规模AI数据中心。
以太网和IB网络“纷争”由来已久,两者在带宽、时延、可靠性、可扩展性差距明显。以太网和IB网最初各自的设计目标和应用场景不同,直接导致两者在性能侧重上存在差异,整体来看,以太网兼容性较高、成本较低、灵活性较好,IB网性能更优秀,具备高带宽、低时延、高可靠性和高可扩展性等优点:延迟:IB网引入RDMA技术,延迟大幅降低。传统TCP/IP协议来自网卡的数据需要先拷贝到核心内存——再拷贝到应用存储空间——再经由网卡发送到Internet,这种核心内存的转换增加了数据流传输路径的长度,传输延迟较大;IB最突出的优势在于率先引入RDMA(远程直接数据存取)协议,允许应用与网卡之间的直接数据读写,同时RDMA的内存零拷贝机制允许接收端直接从发送端的内存读取数据,因此整体CPU负担大幅降低,延迟显著提升。
带宽:以太网和IB网带宽和速率均不断升级。以太网传输速率从10M起步,目前已经发布了100G、200G、400G、800G甚至1.6T以太网接口,传输速率的跨度较大;InfiniBand的网络带宽不断升级,从早期的SDR、DDR、QDR、FDR、EDR、HDR,一路升级到NDR、XDR、GDR。
兼容性:以太网兼容性显著高于IB网络。以太网遵循TCP/IP模型或OSI模型,可以与各种不同的系统和设备互连互通,支持各种网络拓扑,以太网生态系统在产业链中的成熟度更高;IB网络使用自身定义的网络协议,需要特定的软件和驱动才能与其他系统和设备互连互通,甚至不同的应用场景还需要特定IB线缆接入。
扩展性:IB网是针对集群设计的架构,拓展性更高。IB设计之初就支持子网灵活拓扑布局,可以较为简单的添加、重置、删除子网,能够创建具有数千个节点的高性能集群。可靠性:IB网络稳定可靠性较高。IB网是一个完整的网络协议,并具备端到端流量控制,可以避免拥塞、确保信息有序传递、提高网络效率。成本:以太网成本较低,IB成本较高。以太网使用的设备、线缆和接口卡都是标品,供应商和产品可选范围较大;而IB网使用的设备、线缆和接口卡都是专用的,可选厂商较少且客户议价权较弱。
总体来看,以太网作为过去数十年使用最广泛的通信协议,其受众群体众多,用户接受程度高,兼容性强,但因为过去在高性能AI计算场景使用较少,且供应商分散,导致综合效果相较于封闭的英伟达方案有所欠缺。随着大模型超算的持续推进,超以太网联盟的成立,以太网正发起直追,凭借广泛的群众基础,以太网在AI时代依旧有这极强的生命力,与IB的良性竞争也将进一步加速网络架构层面的发展,去匹配持续升级的计算。
1.2.2英伟达:IB和NV网络打造高性能集群
AI时代GPU成为核心处理器,分布式训练诉求提升,集群构架下IB网络优势尽显。GPU采用并行计算方式,擅长处理大量、简单的运算,因此多适用于图像图形处理和AI推理。但是大模型复杂度日益提升,单卡GPU显存有限,无法满足训练需求,需要联合多张GPU甚至多台服务器协同工作,分布式训练成为核心训练方式,集群网络成为趋势,根据以上对IB网络和以太网的叙述中可知,目前来看IB网络的高性能更能满足于AI集群训练的需求。为提高gpu集群性能,英伟达选取IB网络架构,光通信能力成为大模型训练/推理环节的核心能力。英伟达在IB网络早有布局,起初Mellanox是全球IB交换机领先厂商,2019年被英伟达68亿美金收购,当前来看,AI大模型训练均以英伟达的网络配置方案为主,IB网络在大模型应用场景中占据较为绝对的地位,基于英伟达A100、H100、GH200GPU构建的网络基本配套用IB交换机。
(1)A100:目前A100SuperPOD主要用200Gquantum交换机,全200G连接,一条线缆对应2个200G光模块
A100顶配模式:以140台DGX(1120张)的顶配集群为例,在服务器到叶交换机层,每张显卡连接一个叶层交换机口,每个服务器有8张卡,20台服务器分为7组,所以需要7X8台叶交换机与1120条连线;叶到脊层,每组中的8台叶交换机连接分别有一条线连接向10台一组脊交换机,同时UFM管理模块需要分别连接两个脊交换机,共需要1124条连线;脊到核心层,连接方式较为复杂,按照表供需1120条线。
A100标准模式:一个标准的DGXA100SuperPOD部署结构为,140台DGXA100GPU服务器(每台服务器8张GPU)、HDRInfiniBand200G网卡、170台NVIDIAQuantumQM8790交换机(其中交换机速率为200G,每个端口数为40个),采用IBfat-tree胖树网络拓扑。
(2)H100:DGXH100SuperPOD计算集群互联中,理论上需要配置3块800G光模块(2*800G+2*400G)
DGXH100SuperPOD节点内部是NVLink4互联8-GPU,节点之间通过NVLink4Network互联。基本部署结构信息为:32台服务器(每台服务器8张GPU)+12台交换机,网络拓扑结构为IBfat-tree(胖树),交换机单端口400G速率,可合并形成800G端口;交换机建议NVIDIAQuantumQM9700switc。此处我们和A100一样,参考H100的SuperPOD组网白皮书,根据线缆数量计算光模块用量。用于H100计算集群互联中,服务器到叶层需要400G通路,叶层到脊层交换机互联需要800G通路。根据线缆计算,叶层一张H100需要2块400G(1020*2/1016≈2),脊层H100需要2块800G(1024*2/1016≈2),因此,计算集群互联中,约等于需要3块800G光模块(2*800G光模块+2*400G光模块)。故GPU:光模块理论可达极值为:NvlinkSwitch1:4.5+InfiniBand1:3=1:7.5(实际应用中目前因价格过高没有推广,只做空间参考。)
(3)GH100:跨服务器显存共享第一次成为现实
GH100集群架构:三层架构,第一层是显卡,第二层是L1交换机,第三层是L2交换机,每8张显卡与3个L1交换机形成一个POD,或者说“小集群”,每个小集群再通过胖树架构连接到L2交换机,从而实现互联。显卡到L1交换机的距离较短。
1.2.3超以太网联盟:广泛的群众基础,持续优化提高性能表现
超以太网联盟(UEC)成立,有望打破IB网络在AI时代的垄断地位。2023年7月19日在Linux基金会的牵头下成立超以太网联盟(UltraEthernetConsortium),创始成员包括AMD、Arista、博通、思科、Eviden、HPE、Intel、Meta和微软等,EUC目标是超越现有的以太网功能。UEC成立后,以太网与IB网络谁更适合大模型,尚未成定论。当前来看,全球跨服务器AI连接主力军为IB协议与以太网协议。英伟达凭借其领先的显卡性能和用户粘性,使得IB协议在目前的AI连接领域拔得头筹,但IB由于溢价较高,用户往往需要付出更多的隐形组网成本,相同预算下,采购到的显卡,光模块、交换机硬件数量就会较少。当前行业为了改变这种趋势,有两条路线正在浮现,第一是如谷歌等超级巨头,通过全套自研的TPU芯片以及OCS交换系统,以自身技术实力实现生态闭环,从而降低成本。第二则是AMD带领的以太网联盟,以包容,开放的生态,与交换机厂商一起,扩大以太网份额与性能,让更加高性价比的网络惠及客户。我们认为,随着以太网等开放协议渗透率逐渐提升,组网成本中的“隐性花费”有望降低,客户可以将更多的预算投入如高速率光模块、交换机等实际设备的购买中。
以太网的“开放”性能获得AMD大力支持,未来借助开放性或有望与IB网络在AI集群架构中形成竞争力,进一步增加下游客户可选择性,光通信的网络架构渠道得以拓宽。全面拥抱以太网。无论是从显卡服务器设计亦或是网络架构上,AMD全面拥抱“开放”理念,服务器采用标准化设计,可以兼容任何客户的集群。在网络方面,内部互联的InfinityFabric协议将开放给合作的交换机厂商与战略伙伴。同时,在跨服务器的显卡连接上,AMD旗帜鲜明的指出“Ethernetistheanswer”,以太网将成为AMD用于构建集群的协议。相比于业界的另一主流协议IB,AMD认为以太网拥有更好的性能,更好的大规模集群能力,以及最为核心的开放性。
1.3800G/1.6T后全面进入TB时代
AI拉动光模块速率升级,1.6T光模块产品将领衔市场。大模型训练把对算力的需求带上了新高度,当今的AI训练推理亟需超大内存来承载千亿参数量、TB级别大小的大模型,内存性能也顺理成章成为AI算力的瓶颈所在。英伟达H200提前发布,整个技术路线的迭代随之加速,1.6T时代也有望更早来临。高算力、低功耗是未来市场的重要发展方向,随着AIGC发展趋势明朗,高算力需求催化更高速率的800G、1.6T光模块需求。1.6T光模块需求趋势明确,国内厂商加快布局新市场。中国企业已经成为全球光通信产业的重要一极,尤其是光模块领域迅速追赶,已经占到全球50%的份额。从整个产业来看,中际旭创、新易盛、光迅科技、剑桥科技等国内厂商已有1.6T光模块新产品落地,华工科技、联特科技已在研发阶段。
中际旭创:公司1.6TOSFP-XDDR8+可插拔光通信模块,结合了最先进的单通道200G光学技术和行业领先的数字信号处理技术,传输速率达到1.6Tbps,实现了1U机架配置中51.2T的交换机吞吐量,在0-70C温度范围内,以低于23W的低功耗支持2公里的传输距离。公司AI大客户目前已明确提出了1.6T的需求,新产品将根据客户需求进行完善和量产准备,2024年1.6T光模块主要为测试、认证以及小批量需求,真正的规模上量则会在2025年开始。
新易盛:公司1.6T4×FR2光模块产品采用OSFP-XD的封装形式和单波200bps技术,公司采用的技术方案包括EML和硅光子学调制器以及薄膜铌酸锂(TFLN)调制器。1.6T光模块具有4×SN连接器,电接口使用16×100Gbps信号,光学侧使用4×400GFR2信号,模块可以支持长达2公里的传输距离,可用于1.6T的点对点连接或2×800G或4×400G的扇出应用。公司新产品兼具高容量,低每比特成本,低的功耗的特点。
光迅科技:公司1.6TDR8高速光模块,遵循OSFPMSA及CMIS协议标准,采用OSFP-XD的封装形式,模块电接口侧采用16个通道,单通道信号速率100Gb/s;光接口侧采用8通道,单通道信号速率200Gb/s,在整体硬件设计上,该模块采用最新一代5nmDSP,可满足数据中心低能耗诉求,实现10km传输链路预算。在制成工艺上,基于公司成熟稳定的COC(chiponcarrier)以及COB(chiponboard)工艺平台,可保证产品稳定性。
华工科技:公司在400G及以下全系列光模块已实现批量交付,800GLPO系列模块产品已向客户送样,正在验证测试过程中。公司围绕当前InP、GaAs化合物材料,布局硅基光电子、铌酸锂、量子点激光器等新型材料方向,自主研发并行光技术,积极推动新技术、新材料在下一代1.6T、3.2T等更高速产品应用;公司1.6T光模块目前仍在研发阶段,可匹配客户进度及送样窗口。
OFC2023年全球光通信行业风向标,1.6T时代已加速到来。OFC是光通信领域中全球规模最大、专业性最强、影响力最大的国际性盛会,受到全球光通信、芯片乃至云计算公司的高度重视。第48届OFC展会于2023年3月5-9日在美国加利福尼亚州圣地亚哥以现场和虚拟组件的混合形式召开,展会中讨论的热点话题包括量子网络、机器学习(ML)和人工智能(AI)等网络分析技术,以及5G创新等。在本届OFC展会上,国外相关厂商在光芯片、光学元件、电芯片等领域展示了最新的产品和创新。国内参会企业在800G/1.6T光模块、薄膜铌酸锂、硅光、相干光通信等领域也有新产品推出。整体来看,在800G领域,中国光模块供应商已经走在业界前列,200G相关光电芯片产品在展会的亮相,也使得1.6T可插拔光模块的竞争力进一步增加。随着AIGC高速发展下拉动的算力需求大爆发,下游1.6T需求已提前释放,将在2024年全面进入1.6T时代。
二、光子通信新路径—封装与材料的革新2.1封装侧:CPO/LPO/板上光互联
2.1.1传统PAM4+DSP
光模块传输的原理基于光学和电学相互转换,具体包括光接收模块和光发送模块。光模块的原理是,在发射端原始电信号经过驱动芯片处理后,激活半导体激光器或发光二极管发射调制光信号;接收端接收光信号后,光探测二极管将其转换为电信号,经过前置放大器处理后输出。光模块中的主要电芯片包括DSP(数字信号处理器)、LDD(激光驱动器)、TIA(跨阻放大器)、LA(限幅放大器)以及CDR(钟与数据恢复芯片)等。
400G及以上速率的光模块主要有QSFP-DD、CFP8和OSFP封装。随着5G建设、数据要素规模的演进以及AIGC对海量数据传输的需求,电信、数通领域需要更强性能的光交换机,也因此需要更高速率的光模块。目前主流的200G/400G/800G的产品都是基于PAM4技术+DSP芯片来实现高速信号的调制、传输和恢复。PAM4(4-LevelPulseAmplitudeModulation,四电平脉冲幅度调制)是一种调制技术,采用4个不同的信号电平来进行信号传输,每个信号周期可以传输2bit信息。传统数字信号通过不归零编码(Non-Return-to-Zero,NRZ)来传输信号,只有高、低电平代表1、0两种信号,每个信号周期能够传输1bit信息。PAM4能携带NRZ两倍的信息量,从而实现传输速率的倍增。PAM4的优势在于可以在不增加带宽的情况下提高传输速率,缺陷在于对噪声更敏感,其眼图开口更小,难以将原始信号区分开来。
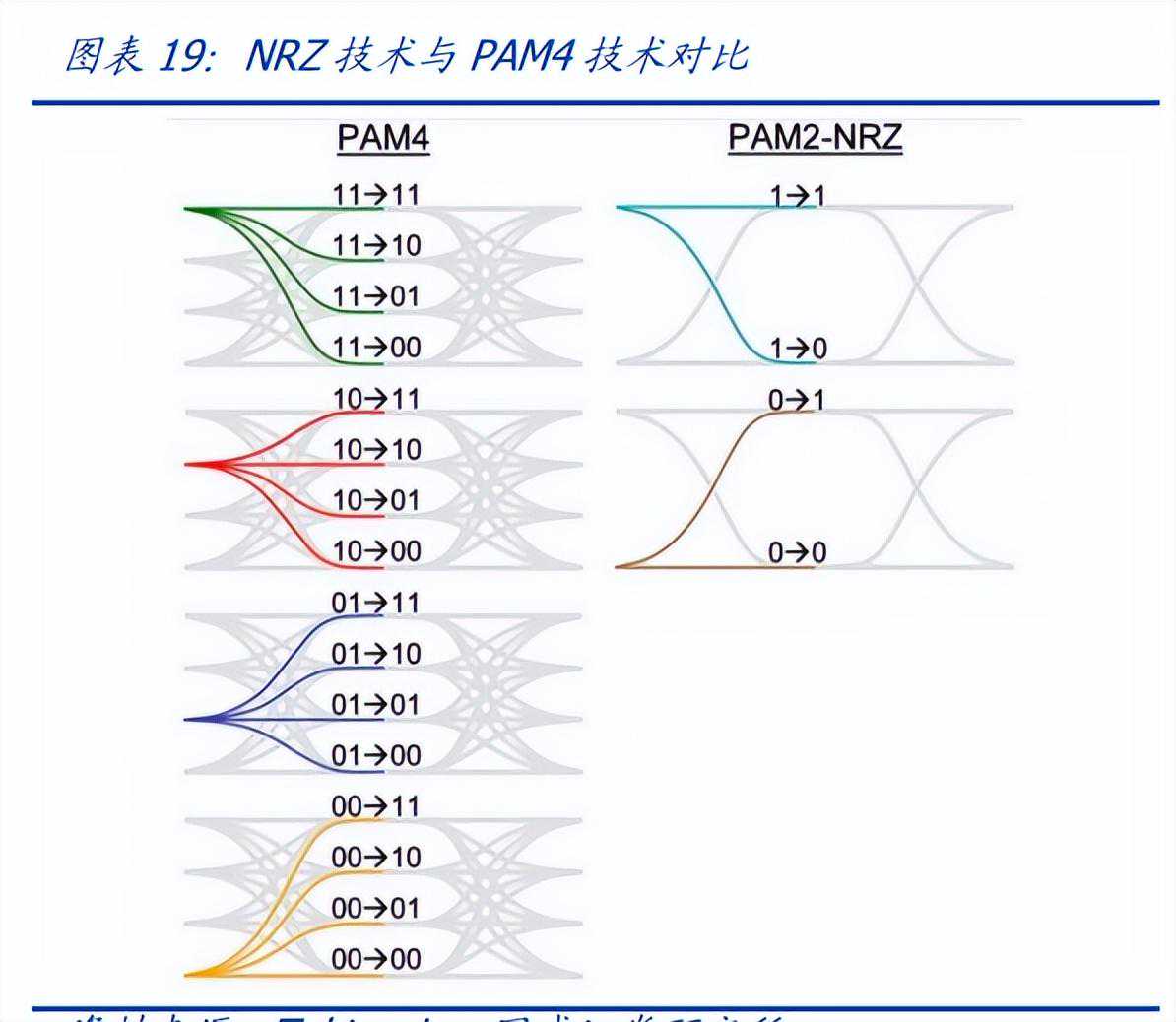
PAM4的调制方法包括基于DSP的数字DAC实现方法和基于模拟的组合方法。主流模拟模式可以通过添加两个NRZ信号通道来工作,数字模型基于高速DAC,可实现0/1/2/3电平的快速输出。DSP是数字信号处理技术,主要用于解决光通信系统中的数字时钟恢复、色散、带宽不足引起的低通滤波效应、偏振旋转等问题,消除噪声和非线性干扰。对于100G以上的单波应用,目前的电驱动芯片和接收端光器件无法达到50GHz以上的带宽,相当于在发射端引入低通滤波器,造成码间干扰,使得接收器无法恢复正确信号。引入DSP后,信号可以在发送端进行压缩,在接收端通过自适应非递归(FIR)滤波器恢复,从而减少对光器件带宽的要求。PAM4+DSP解决方案具有较好的信号处理能力,表现在电口适应性强、光电性能好等,但具有更高的功耗和成本。
目前PAM4+DSP是应用相对广泛并且性价比较高的传统主流方案,但有进一步性能提升空间。在高速通信领域,PAM4逐渐成为一种重要的调制方式,尤其在数据中心和光通信系统中得到广泛应用,是400G光模块的主要调制方式。PAM4调制在电口适应性强、光电性能好,但在功耗和成本上有进一步提高空间,在400GZR中DSP模块功耗占比49%,在成本上,DSP价格较高,400G光模块中,DSP的BOM成本约占20-40%。
2.1.2CPO共封装是长期方向
CPO(Co-packagedOptics)是一种在数据中心光互连领域应用的光电共封装方案。CPO方案通过将光模块与交换芯片进行共封装,可以降低成本和功耗。长期来看,CPO是实现高集成度、低功耗、低成本、小体积的最优封装方案之一:减少走线距离:CPO将光模块逐渐靠近交换芯片,缩短了芯片和模块之间的走线距离,从而提高了数据传输的效率和速率。绕过DSP和散热结构:CPO方案绕过了光模块中的DSP单元和散热结构,采用硅光子模块和超大规模CMOS芯片的共封装方式,以提高整体的集成度和降低功耗。优化成本和功耗:减少元器件的复杂性,采用共封装的方式,实现了对成本和功耗的双重优化,使其更适用于大规模数据中心的部署。
目前由于技术和产业链尚未完全成熟,CPO在短期内可能难以大规模应用,但其在未来共封装光学的思路有望逐步替代传统的可插拔光模块,CPO有望为数据中心光互连技术提供更紧凑、高效、低功耗的解决方案。
2.1.3LPO,800G时代最具潜力的方案
LPO简介:LPO(lineardrivepluggableoptics,线性驱动可插拨光模块),主要运用于高速光模块领域,就是通过线性直驱技术替换传统的DSP,实现系统降功耗、降延迟的优势,但系统误码率和传输距离有所牺牲。该技术适用于数据中心等短距离传输场景。LPO技术主要用于高速率光模块中。光模块传输速率涵盖很大的范围,根据传输速率的不同,光模块可分为155M、622M、1.25G、2.5G、8G、10G、16G、25G、32G、40G、50G、100G、200G、400G等。传输速率越高的光模块,结构越复杂。根据封装类型的不同,光模块可分为SFP、eSFP、SFP+、XFP、SFP28、QSFP28、QSFP+、CXP、CFP、CSFP等。
LPO方案相较于PAM4+DSP有何优势?为了降低DSP的功耗和延迟,LPO概念应运而生。LPO技术去掉了DSP芯片,将其功能集成到交换芯片中,只留下驱动(Driver)和跨阻放大(TransimpedanceAmplifier,TIA)芯片。LPO光模块中用到的TIA、driver芯片性能有所提升,从而实现更好的线性度。但是,LPO的系统误码率和传输距离有所影响,因此这项技术只适用于短距离的应用场景,例如数据中心服务器到架顶交换机的链接。
LPO技术具有以下几个优点:(1)低功耗。LPO功耗相较可插拔光模块下降50%,与CPO接近。根据Macom的数据,具有DSP功能的800G多模光模块的功耗可超过13W。而利用MACOMPUREDRIVE技术的800G多模光模块功耗低于4W,下降70%。低功耗不仅节省电能,而且能够减少模块内组件的发热。(2)低延迟。去掉DSP芯片后,系统减少了对信号复原的时间,延迟大幅降低。DSP/重定时功能增加了延迟,以MACOMPUREDRIVE技术为例,因采用信号串行方案,LPO光模块可以做到皮秒级别的延迟时间。(3)低成本。DSP价格较高,400G光模块中,DSP的BOM成本约占20-40%;LPO的Driver和TIA里集成了EQ功能,成本会较DSP上浮少许,但LPO方案还是可以将光模块成本下降许多。(4)可热插拔。相比于CPO,LPO没有显著改变光模块的封装形式,采用可插拔模块,便于维护,并且可以充分利用现有的成熟技术。
值得注意的是,LPO方案需要和交换机进行配合,对光模块厂商在产业内上下游合作协同要求更高,龙头公司如中际旭创、新易盛将更加具备优势。
2.1.4光互联的进化:向短距离渗透,向高密度升级
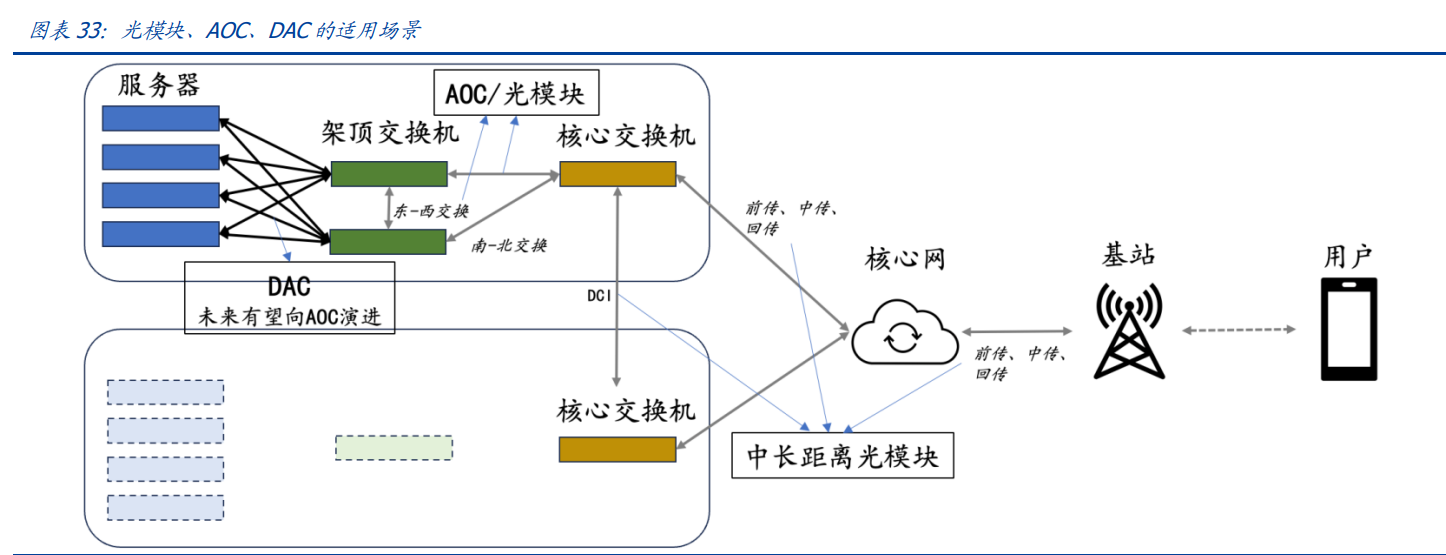
点到点连接层面,冯诺依曼瓶颈凸显,光互联的两端,距离越来越短。从分布式数据中心互联,到AI超算中心的机架间光互联,甚至芯片间光互联、存储介质间光互联,可以说,光纤两端的距离正在缩短。究其原因,是“冯诺依曼瓶颈”凸显:电子在处理器和内存之间的传输速度因带宽和物理延迟而被限制,将数据传输通道改为光子,或将有效解决冯诺依曼瓶颈。将以上假设聚焦到AI新品AI超算中,我们发现,光连接需求大幅增长。为匹配高性能芯片的计算能力,通信网络带宽和器件用量双增长。根据英伟达发布会,一套满配的GH200将用到241芯公里的光纤;华为星河AI白皮书中提到要使用“高吞吐”网络以充分释放AI集群算力,主板之间体现在“端口高吞吐”,机架之间体现在“网络高吞吐”,我们认为,光连接在整个算力系统的价值量将持续提升。AOC是一种性价比高、易于维护的光连接解决方案。AI超算和DCI场景中,主流连接方案是光模块+光纤、AOC(ActiveOpticalCables,有源光缆)和DAC(DirectAttachCables,直连电缆)三种,前两者的区别在于,AOC将光模块和光缆集成化,避免光口被污染的可能性,以提升可靠性。对于后两者,此前在端口速率低于400G的时代,DAC凭借极低成本成为市场主流,后来随着端口带宽进一步提升和多模光模块成本降低,采用光传输的AOC方案赢得青睐,DAC未来有望加速向AOC升级。
面到面交换层面,ROADM进化出OXC,光交换建起更加高效、易于维护的“立交桥”系统。ROADM(ReconfigurableOpticalAdd/DropMultiplexers),可重构光分插复用器,现今广泛用于骨干、城域和数据中心互连(DCI)的组网需求。随着光互联的密度大幅增加,传统的集成度较低的ROADM无法满足需求,且维护效率低,进而衍生出集成度极高的OXC(opticalcross-connect)。我们认为,OXC目前广泛用于电信骨干传输网络,未来有望应用于交换网络同样复杂、密集的AI超算内部或分布式超算互联网络中。
根据中兴通讯的实践,20维的ROADM需要站点内3个机柜、100多块单板、400多根光纤;OXC采用高度集成的单板和光背板,减少了占地面积和功耗,并简化了内部光纤连接。20维的OXC只需要1个机柜、约30块单板,同时也降低了相应的功耗。光线柔性板连接节点内所有光纤,实现自动连纤,提高配线效率,降低维护成本。
2.2材料侧:硅光/薄膜铌酸锂
光通信系统中电光调制器是关键环节,通常可以按照材料平台分为三大类别。电光调制器通过调制将高速电子信号转换为光信号,制备电光调制器有三种较为常见的方案,可以按照材料的不同划分为磷化铟方案、硅光方案、铌酸锂方案。磷化铟调制器目前使用较为广泛,且历史较久,适合中长距离光通信网络的收发模块,但存在尺寸、功耗、成本较高的欠缺,因此材料侧也出现了硅光和薄膜铌酸锂两种较为创新的平台,铌酸锂方案又可以分为传统铌酸锂和薄膜铌酸锂方案,前者适用于长距离、大容量传输场景,但由于体积较大,与光器件小型化的发展趋势相悖,且难以进行大规模晶圆制造;而薄膜铌酸锂调制器尺寸更小、损耗和功耗较低、带宽更大、成本更低,是更为理想的材料平台。
2.2.1硅光
老生常谈“硅光”。硅光技术提出已久,当市场广泛讨论硅光技术,默认指的硅光技术的“最终集成模式”即硅光模块,但其实严格意义来看,硅光技术包含了三类产品:硅光器件、硅光芯片、硅光模块。硅光器件是基础硬件,包括光源、调制器、探测器、波导等;硅光芯片是将各发送/接收/探测/调制芯片等集中在一起的单芯片,具备高性能、低功耗、低成本等优点;而硅光模块是硅光技术的集大成者产品形式,将光源、硅光芯片和模块如光发送器件和光接收模块、甚至外部驱动电路等都集中在一起的一体化模块。
硅光本质上是硅基光电子大规模集成技术,较传统方案更具优势,集中体现在速率高、成本/功耗低、集成化程度高、体积更小等方面。硅光技术是一种利用硅材料的光学和电学特性来实现光学器件的制造和集成的技术,硅作为主要材料,通过在硅基底上制备光学元件,如波导、光调制器、光耦合器等,从而实现在硅芯片上集成光学功能,此外硅光材料还是光电共封装CPO技术的基础。相较传统光模块,硅光技术成本、能耗、体积更低:
集成度高:硅芯片是集成电路制造中常见的材料,硅光技术可以与传统的半导体制造工艺相兼容,实现光学器件的高度集成,减小整个光学系统的体积。制造成本低:硅是广泛使用的廉价半导体材料,硅光技术相对于其他光学材料的制造成本更低,有利于大规模制造和商业应用。兼容性强:硅光技术可以与现有的电子集成电路技术兼容,使得光学器件可以与电子器件在同一芯片上集成,实现光电混合集成,易于与CMOS电子器件集成是硅光技术的关键优势之一。带宽高:硅光技术借助光互连实现低能耗和低散热,有效避免了解决网络拥堵和延迟,激光代替电子信号传输又加快了传输速率。短距离通信应用:硅光技术主要应用于短距离通信领域,例如数据中心内部的通信,因为硅光器件对于短距离通信的需求具有良好的性能。
硅材料自身应用历史悠久,掣肘硅光技术发展难点集中于光激光器,技术升级突破进展中。硅基材料自身发光效率较低,光激光器成为技术痛点,因此市面上主要硅光方案一般是CMOS方案(采用大规模集成电路技术工艺集成单片硅光引擎)或者混合集成方案(光芯片仍使用传统的三五族材料,再将三五族的激光器与硅上集成的调制器、耦合光路等加工在一起)。不过根据C114信息,硅光最近的突破性进展引入了在硅上制造有源光学元件的创新方法,并在几年内实现了量产,未来硅光技术进展有望加速。
从工艺角度来看,硅光可以分成单片集成和混合集成,目前混合集成使用较广,但是单片集成性能更优,是未来发展趋势。单片集成是指将光子学组件直接集成到同一块硅芯片上,包括光源、光调制器、波导、耦合器等光学元件,统一被整合在硅芯片上,从而形成一个紧凑的光学电路,单片集成方式的优势在于可以减小尺寸、提高集成度,并降低制造成本。混合集成是指将硅芯片与其他材料的光学组件结合在一起,即将电子器件(Si-Ge、HBT、CMOS、射频等)、光子器件(激光/探测器、光开关、调制解调器等)、光波导回路集成在一个硅芯片上,其中硅芯片主要负责电子部分的处理,而其他材料的光学元件则负责光的生成和调制,混合集成的优势在于可以利用硅芯片的电子器件和其他材料的优异光学特性,实现更高效的光通信和传感应用。目前来看,光器件如波分复用器、变换调谐器等已经可以实现单芯片集成,而光模块尚需要混合集成。
制造工艺是限制硅光光模块发展的瓶颈,封装工艺却为硅光光模块带来新的希望,,AI大模型引发算力革命下,CPO加速推动硅光加速,共振引领光通信走向代际更替。前文提到的CPO是把硅光模块和CMOS芯片共同封装的技术,缩短了光学引擎和交换芯片的连接距离,从而降低传输损耗,速度与质量双提升,除了硅光的制造工艺,光模块的封装技术与硅光落地难度密切相关,共封装技术进一步降低了硅光单片集成的难度,未来两者有望形成良性循环,将光通信从800G/1.6T时代加速引向硅光时代。800G/1.6T时代已来,硅光前景光明。AI的爆发使得800G时代加速到来,而随着硬件的竞争迭代加速,光通信对应速率也明显缩短,我们预计2024年1.6T整体进展有望持续加速,2025或将迎来1.6T批量交付。产品代际迭代周期的缩短,光模块厂商对新技术新材料将更加开放,硅光在高速率背景下有这比较明显的纸面优势,整体进展有望持续加速,硅光份额在未来数年有望实现持续的提升。
2.2.2薄膜铌酸锂
薄膜铌酸锂——“光学硅”。铌酸锂材料是可靠材料中电光系数最优的选择(考虑居里点和电光系数)。薄膜工艺拉进电极距离,降低电压提升带宽电压比。相比其他材料兼具大带宽/低损耗/低驱动电压等诸多光电最需要的优点。当光模块切换到1.6/3.2T阶段,有望向单波200/400G演进,薄膜铌酸锂的大带宽优势将更加突出。薄膜铌酸锂有何优势?传统的体铌酸锂波导层的芯层-包层折射率差非常小,带来波导模场太大的问题;波导模场面积很大,相应的电极之间的距离就会随之增加,那么实现电光调制就需要外加足够大的驱动电压来获得足够的电场,功耗难题凸显。而薄膜铌酸锂的优势是可以采用刻蚀等方法制作强限制的波导模场,利用这种工艺可以将电极置于离波导模场很近的地方,从而降低驱动电压。同时,薄膜铌酸锂还顺带解决了带宽问题:调整薄膜铌酸锂波导模场包层(硅/二氧化硅)的厚度就可以实现不同带宽。这样一来,薄膜铌酸锂可以同时实现极宽的带宽、低调制电压、低损耗和更好的传输效率。铌酸锂进入门槛较高,全球玩家稀少。铌酸锂调制器设计难度大,工艺复杂,技术门槛高,全球仅三家光通信厂商可以批量生产电信级别的铌酸锂调制器:日本的富士通(Fujitsu)和住友(Sumitomo),美国Lumentum的铌酸锂调制器生产线(2019年由光库科技收购)。其他头部光通信设备厂家在计划研发或正在测试薄膜铌酸锂调制器产品。
三、光子的现在与未来—光交换/光计算3.1谷歌的光交换OCS体系
谷歌数据中心网络深度转型,OCS顺利上马。为解决传统电交换机功耗较高、存在一定通信延迟、通信协议异构、需要频繁升级换代的问题,谷歌应用了光路交换(OpticalCircuitSwitching,OCS)技术,通过两组微机电系统(MEMS)棱镜动态地将光纤输入端口折射到输出端口,这些镜子可以进行二维旋转,自由构建端口到端口的光路。OCS颠覆了传统电交换机的原理,服务器发出来的数据包无需经过光电转换,也就是无需“换乘交通工具”,极大降低了数据传输的延迟。
使用MEMS光路开关芯片的优势在于,可以实现低损耗,低切换延迟(毫秒级别)、低功耗、低成本。MEMS光开关的关键部件有:a)光纤准直器,b)相机模块,c)封装MEMS阵列,d)注入模块,e)二向色分光器和组合器。以Palomar型号为例,其使用两个MEMS反射镜阵列工作。由绿线指示的带内光信号路径,与带内信号路径叠加,850nm波长通道(红色)用于调节反射镜。不需要光到电到光的转换或耗电的网络分组交换机,从而节省了电力。
3.2Intel等为主的光计算芯片
当下,摩尔定律瓶颈问题凸显。目前台积电的商用制程已经达到5纳米级别,在研制程已经升级到3纳米,并有望在2024年放量。3纳米若再进一步升级制程就会触及原子级别尺寸的微观空间,如此狭小的蚀刻电路沟槽中,晶圆的良率难以保证致使芯片制造成本飙升,同时,“短沟道效应”凸显,5纳米芯片普遍出现漏电现象,最终令芯片发热量增加,耗电失控。因此,寻找一种可以突破摩尔定律极限的新型计算方式迫在眉睫。
光子具有光速传播、抗电磁干扰、光波任意叠加等特性,因此光子天生适合做数据并行传输,因而光子芯片运算速度极快。光子学技术在计算机中的应用包含两个层次,一个层次是利用光子作为传输信息载体的光互联技术,另一个层次是直接在光域实现信息的处理和运算。光计算芯片可以分为模拟光计算和数字光计算。模拟光计算最经典的就是计算机视觉中的傅立叶变换,传统的进行二进制计算的点芯片处理傅立叶变换积分会消耗很大一部分算力,然而光通过透镜的过程本身就是一次傅立叶变换。数字光计算与电计算相似,通过构建逻辑门实现计算。
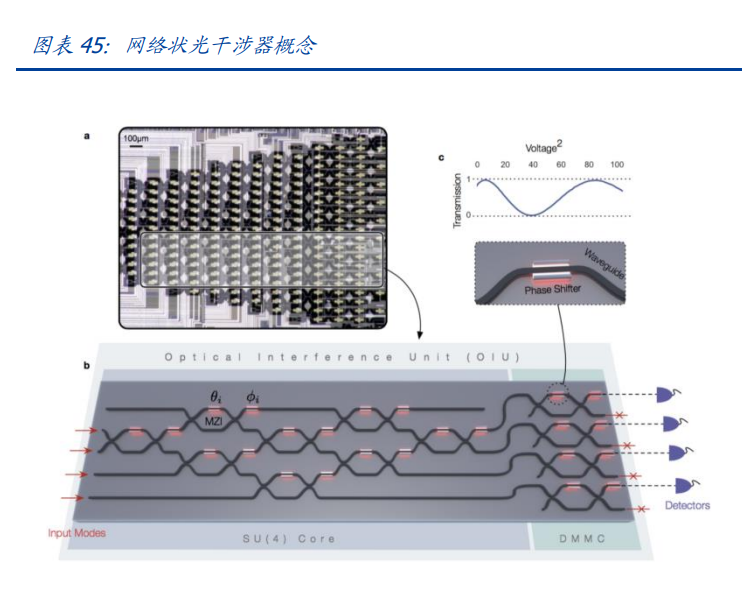
前沿学界正在尝试将光互联搬进芯片内。芯片外的光互联尺度已经越来越短,那么,在芯片内若将电子结构一并改为光子结构,从理论上说可以进一步增强芯片性能,同时,由于无需光电/电光转换,能耗进一步降低。光透镜实现可编程,是光计算的重要里程碑。2017年,沈亦晨等人发表了《Deeplearningwithcoherentnanophotoniccircuits》,开创性地提出可编程光计算单元,该论文提出一种网络状干涉器,在光通过干涉器的时候,利用它们相互之间的干涉和对干涉器的控制来进行线性运算,可以总结为用一个干涉器的集联来完成大规模的线性计算,以此应用于人工智能的矩阵计算。2023年5月31日,中科院半导体研究所研制出一款基于光学计算的卷积处理器,与其他光计算方案相比,该方案具有高算力密度和线性扩展性的优点,这标志着我国在光计算方面有了重大突破。
4.1卫星光—星间激光
将光通信带入卫星一直是全球产业链发展的重要方向,与传统的微波或者无线电通信相比,激光通信具有需要功率小,通信速率高,保密性好等特点,尤其是在卫星通信频谱资源日益拥挤的时代,无需专用频谱的卫星激光通信有望加速发展,但与之相对的是,星地之间的气象条件复杂,星地之间瞄准与捕获机制复杂等等痛点,一直制约了星地激光通信的发展。从目前来看,虽然全球各国都积极进行了相关实验卫星或实验项目的尝试,星地激光通信要成为主流仍然有较长的路要走。
但随着低轨星座的发展,星与星之间的激光通信有望率先起量,星间激光通信是指利用激光束作为载波在空间进行图像、语音、信号等信息传递,具有传输速率高、抗干扰能力强、系统终端体积小、质量轻、功耗低等优势,可以大幅降低卫星星座系统对地面网络的依赖,从而减少地面信关站的建设数量和建设成本。除了继承了上文中提到的优点外,由于星座间两星的距离较短,同时发射端与接收端同处于太空环境中,不会受到云雨气象条件干扰的同时,激光的发射与捕获环节的技术难度也相较星地通信低。全球较早搭载星座间激光通信系统的是Starlink的卫星,最早的三颗卫星于2021年6月发射,截止目前,共有近3000颗卫星在轨运行,凭借星间激光通信,星链得以像诸如南极洲等信关站难以部署的地区提供稳定的卫星互联网服务。
与传统的地面光通信类似,卫星激光通信所用的设备也由光学部分和电学(通信)部分组成,与地面不同的是,卫星上由于两颗卫星之间相对位置高速变化,对于接受系统也提出了更高的要求。
光学分系统由光学天线、中继光路及各收发光学支路构成,各部分紧密衔接,共同实现激光信号的高质量收发。跟瞄分系统由粗跟踪单元、精跟踪单元、提前量单元等构成,主要完成空间光信号的瞄准、捕获、跟踪,利用具备方位和俯仰功能的跟瞄转台,加上控制信号的计算与处理,实现需要通信的两颗卫星激光通信光学天线的精确对准,并保证双方互发的激光信号能通过光学分系统进入对方的通信分系统。通信分系统由激光载波单元、电光调制单元、光放大单元、光解调单元等构成,主要完成卫星激光通信系统光信号的调制/解调、光放大及信号处理等功能。从目前的主流方案来看,主流的星间激光通信主要有两种调制方式,非相干与相干,非相干通信体制采用强度调制/直接探测(IntensityModulation/DirectDetection,IM/DD)方式,分为开关键控(On-OffKeying,OOK)和脉冲位置调制(PulsePositionModulation,PPM)。相干通信体制采用相位调制/相干探测方式,分为二进制相移键控(BinaryPhase-ShiftKeying,BPSK)/零差(外差)相干探测、差分相移键控(DifferentialPhase-ShiftKeying,DPSK)/自差相干探测、正交相移键控(QuadraturePhase-ShiftKeying,QPSK)/零差(外差)相干探测等。相干调制具有精度高,传输速率高,传输距离长等特点,但是由于其需要额外的电路元件,同时由于运行环境处于太空,需要对这部分电路元件进行抗辐照处理,因此成本较高。
由于目前Starlink尚未公布其星间卫星通信的主要参数,我们只能参考当前主流的卫星激光通信产品的参数与调制方式。从已公开数据来看,当前海外主要低轨星座的卫星组件都采用了相干中的BPSK调制模式,主流通信速率均为10Gbps左右。
我国的光通信行业经过多年发展,在相关激光器,光放大器等组件上已经形成了较为成熟的产业链,卫星通信上的光学部分与通信部分与地面光通信有着较高的相似度,我国有望凭借在传统光通信行业上的深厚积累,快速追赶欧美先进水平,除了国产星座搭载激光通信载荷外,随着全球星间激光链路放量,国内光器件厂商也有望切入全球市场。
4.2汽车之光—激光雷达
激光雷达是以发射激光束对目标进行探测、跟踪和识别的雷达系统,激光雷达通过将接收到的反射信号与发射信号进行比较、进行数据处理之后,可获得目标的距离、方位、高度、速度、姿态甚至形状等特征参数。激光发射系统:用于制造、生成激光,光线经由激光发射器发出,通过控制光线方向和线数的光束控制器,最后通过发射光学系统校正后发射。激光接收系统:被反射的光经接收光学系统汇集后,光电探测器将接收到的反射光转化电信号。信息处理系统:接收到的信号经过放大处理和数模转换,经由信息处理模块计算,获取目标表明形态、物理属性等特性,最终建立物体模型。扫描系统:主要用于扩大光源的探测范围,并产生实时的平面图信息。激光雷达光通信,产业进入加速整合期。激光雷达产业链与光通信行业具有高度协同相关性。
首先,从产品结构看,光模块和激光雷达主要部分均包括激光发射模块和接收模块。光模块实现光电信号的转换,主要包括TOSA、ROSA以及滤光片、棱镜等光学元件,其中TOSA中的主要器件为激光发射器和激光驱动器,ROSA中的主要器件为探测器和放大器。其次,从激光波长来看,光模块和激光雷达的光波段高度重合。光通信主要采用波长为850~1650nm的电磁波,目前重点应用的波长有850nm、1310nm和1550nm三种,对应频率由高至低,传输距离由短及长。而激光雷达的主流波长为905nm和1550nm,与光通信波段高度重合。905nm和1550nm方案有何不同?905nm方案可以用硅做接收器,成本低且产品成熟;1550nm需要用Ge(响应速度稍低)或者InGaAs探测器,且该波段对人眼更加安全,这样可以发射更高的激光功率以达到更高的测距灵敏度和信噪比。我们认为,两种方案未来有望相辅相成,1550nm雷达可用于检测汽车前方或后方数百米的障碍物,更便宜的905nm雷达则专注于感知汽车周围环境。
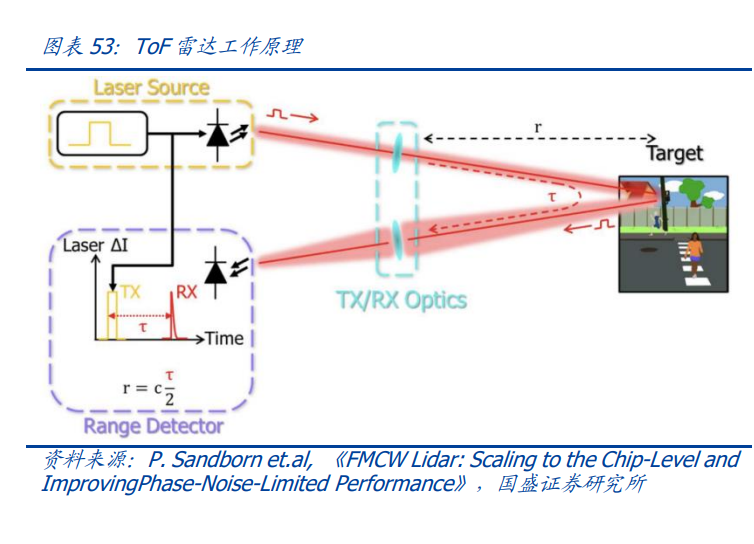
将三者对比来看,ToF最大的优势是利用现有的光通信产业链能迅速搭建测试环境,产业化进程较快。从长远来看,FMCW通过出色的环境光抗干扰性能、人眼安全性、高信噪比、更远的探测距离,有望占据激光雷达市场的一席之地。此外,从激光器技术路线看,均主要采用EEL和VCSEL激光器。车载激光雷达主流采用EEL和VCSEL两类半导体激光器,而在光模块的TOSA组件中,同样以半导体激光器类型为主,VCSEL主要用于多模光纤模块,DFB/FP/DBR主要用于单模光纤模块。最后从生产工艺和产线的角度看,激光雷达本身量级较光通信体量差距较大,光通信厂商可复用现有产线快速进行切换,其成本可控。光通信厂商可以满足激光雷达产业链快速扩产的要求。随着激光雷达的陆续上车和点云数的提升、摄像头和超声波雷达的数量和精度增加,使得大算力冗余、算力先行成为主机厂的共识,以提高车端神经网络算法的深度和精度,带来实时行车场景数据识别准确率、L3、L3+高阶自动驾驶落地确定性的提升,2023年进入智能汽车算力“军备竞赛”元年,我们预计,2024年将进入大规模放量元年,加速汽车产业L3及L3+智能驾驶渗透率的向上拐点。据沙利文数据预测,2025年中国激光雷达市场规模有望达到43.1亿美元,较2019年实现63.1%的CAGR。
头部激光雷达公司营收持续增长,映证激光雷达需求。随着产业链趋于成熟,激光雷达行业参与者众多,竞争较为激烈,但头部厂商仍然保持着营收体量稳健上涨的势头,证实了激光雷达潜在市场广阔,能够容下较多厂商参与。
中低端车型迎来激光雷达市场下沉,高端车型单机线数“内卷”。随着激光雷达成本不断降低,以往只有理想L7等高端车型才能选装的激光雷达下沉至20万元左右的中端车型,我们认为未来有望进一步下沉至10万级别的低端车型中。高端车型上,为提升激光雷达分辨率和识别稳定性,单机线数竞争激烈,12月底发布的问界M9配置192线激光雷达,最远可探测距离达到250米,点频达到业界最高的184万点/秒,扫描频率达到20Hz。
总结来看,激光雷达是光通信产业链切换下游赛道获得全新增长空间的优良机会,伴随激光雷达技术成熟度越来越高,叠加L3级别自动驾驶铺开,激光雷达有望迎来广阔市场空间,带动上游光通信获得全新的EPS增厚的机会。
五、边缘计算:始于AI,赋能应用5.1模型由大到小,AI走上应用的快速路
随着GPT-4的发布,标志大语言模型正式迈入了多模态时代,参数量近一步膨胀。4月份,OpenaI创始人SamAltman在一场MIT举办的活动上表示,“未来的AI进展不会来自于让模型变得更大”,我们认为,这代表着OpenaI之后的努力将会更多的转向如何让现有的大模型更好用,渗透进更多的场景。2023年五月初的几大变化,让我们更加坚信了,万物搭载模型,模型赋能万物的时代正在加速到来。知名华人AI研究者陈天奇牵头开发的MLC-LLM解决方案,MLCLLM为用户在各类硬件上原生部署任意大型语言模型提供了解决方案,可将大模型应用于移动端(例如iPhone)、消费级电脑端(例如Mac)和Web浏览器。
MLC的主要功能包括了:(1)支持不同型号的CPU、GPU以及其他可能的协处理器和加速器。(2)部署在用户设备的本地环境中,这些环境可能没有python或其他可用的必要依赖项;通过仔细规划分配和积极压缩模型参数来解决内存限制。(3)MLCLLM提供可重复、系统化和可定制的工作流,使开发人员和AI系统研究人员能够以Python优先的方法实现模型并进行优化。MLCLLM可以让研究人员们快速试验新模型、新想法和新的编译器pass,并进行本地部署。
MLC-LLM等模型给中小开发者提供了低成本,快速训练专属于自己的小模型的完整工具,而MLC-LLM则为中小开发者在算力较低的环境或者边缘进行模型的推理搭建了基础,三大工具,我们认为已经形成了AI走向边缘的“基建雏形”。硬件赋能,AIGC在边缘端的革命进一步加速。2023年2月,高通演示了10亿参数规模的StableDiffusion,6月完成了在终端运行参数量更大的图生图模型ControlNet。在2023骁龙峰会上,高通推出新一代旗舰移动芯片骁龙8Gen3、旗舰PC芯片骁龙XElite和音频芯片S7系列。其中骁龙8Gen3专为AIGC定制,与前代相比,其AI性能提升98%,支持本地运行100亿参数的大模型;骁龙XEliteAI处理速度达到竞品的4.5倍,异构AI引擎性能达75TOPS,支持本地运行130亿参数的大模型。本次发布的骁龙8Gen3进一步为边缘端大模型优化,不到1秒就能使用StableDiffusion生成1张图像,在运行70亿参数的大语言模型时,每秒可以生成20个Token,超过了人类阅读的速度。我们认为,云端协同的“混合AI”路线有望帮助移动端AI应用成长为“完全体”,手机进行内容输出的效率远低于PC,但未来在本地运行的AI加持下,用户得以将少量的输入转化为大量输出,这便是混合AI的重要意义之一。
“本地运行AIGC”有望成为智能手机、PC的新卖点。AI能力近年始终作为智能手机的辅助功能,常用于广告算法、应用推荐、照片标记等不痛不痒的后台能力。当下随着终端芯片足以支持本地大模型快速处理Token,AI能力有望走向台前,和用户直接交互并生成内容。本地推理大模型在成本、时延、隐私上具有天然优势,也可以作为桥梁,预处理海量复杂Token,并将其导向云端大模型,搭载AI能力的终端芯片,作为AI触及万千场景的血管地位加速明晰。消费电子近年来始终存在创新困局,而混合AI的出现,有望创造新的使用场景从而刺激终端换机。英特尔发布酷睿Ultra处理器,开启AIPC新纪元。AIPC集成了AI应用加速NPU单元,可以方便地让用户通过大模型进行新的交互并有效地提高日常办公的效率和质量,同时也在有望PC上部署专业的边缘AI模型进行本地化AI创作,AIPC有望彻底改变PC用户的使用习惯和场景,也改变了PC产业的发展未来,PC由个人计算终端升级成了个人AI应用中心。
总结来说,除了开源社区、前沿学者正在不断加速模型的可用性,以及边缘推理的探索,越来越多的大厂也加入到了布局边缘模型的新一轮“军备竞赛”中来,我们认为,随着两方的共同努力,一个由“基础模型”,“低成本定制工具”,“模型优化工具”三者共同构建的边缘模型生产与利用体系将会飞速发展。AIoT类业务2023年受到消费需求以及价格竞争影响,整体处于预期低位,2023年,高算力骁龙、英特尔新品完成硬件铺路,可以静待后续应用跟进。
5.2应用曙光已现,期待AI飞轮下的百花齐放

边缘应用方向1:基于生成式模型的“智能助理”
智能助理这一概念,最早火爆,是伴随“Siri”的推出,消费者第一次系统性的认识到了基于语音唤醒的智能助理这一概念。然而随着多年发展,这一形式的智能助理除了搭载平台扩充到了如车机、智能音响、扫地机器人等平台外,其本质内核仍然没有改变,依旧是基于对语音输入关键词的截取,在功能库中寻找对应的功能。并不具备主动生成的能力。AIAgent(人工智能体)在大模型快速发展的驱动下进入加速成长期。诸如GPT等LLM应用在更新信息、处理多轮对话和面对复杂任务时依然存在局限,AIAgent通过增加规划、记忆和工具使用三大能力克服了这些局限,极大扩展了大语言模型的应用范围,使其能够胜任更加复杂的任务,这为AIAgent扮演人类日常生活的“助理”提供了可能。
汽车是AIAgent最具潜力的应用场景之一。车主在驾驶时,需要既快又准地对汽车进行操作,在座舱还未智能化的时代,这种操作依靠机械按钮、操作杆进行,而未来的人车交互愈发向中控屏幕集中,传统的操作习惯就需要改变。而AIAgent的能力则贴合了这种需求:快速响应、准确理解命令和无手操作,而AI赋予的智能化可以将Agent的能力进一步外延,这些抽象的能力具象到应用场景中,可以将AIAgent的能力总结为5个层次:辅助操作、车身数据采集可视化、汽车服务(导航、保养、保险等)、生活助理、具身智能。
此外,我们观察到了海外爆火的应用“Rewind”,通过记录笔记本电脑的屏幕输出信号与麦克风信号,并形成数据库,最后基于这些数据库与自有模型,帮助用户回忆,总结在电脑上看到的,处理过的所有资料,大大提高了用户的工作效率。
基于两点应用方向和现在出现的应用趋势,我们判断,边缘算力将在“智能助理”类应用的发展和商业化上起到重要作用,第一,智能助理面对的是海量用户,这些用户所提出的Prompt将是及其复杂或者存在非常多的冗余,如何通过本地小模型,对用户的需求进行预处理,从而将需要云端算力处理的Token将至最低,甚至对于不复杂的推理需求,可以通过本地算力直接响应客户需求。第二,对于像“Rewind”、汽车智能座舱这类涉及到用户隐私资料的部分,为了保证用户安全,所有的数据归纳将会完全依靠本地算力进行。因此,在降本,隐私方面,边缘算力对于“生成式智能助理”能否形成商业闭环,至关重要。
边缘应用方向2:具身智能
具身智能是指能够理解、推理并与物理世界互动的智能系统。AIGC的“智能”表现在能够进行上下文理解和情景感知,输出文字、图像、声音,而具身智能能够在物理世界中进行操作和感知,输出各种机械动作。通过物理环境的感知和实际操作,具身智能可以获得更全面的信息和数据,进一步提高对环境的理解和决策能力。按照具身智能的定义,目前具身智能的实例繁多,其中包括人形机器人、自动驾驶汽车等。基于现在具身智能展现出的能力,我们认为,具身智能的两大核心是负责算力的芯片和与外部通信的模组。当前物联网模组进入智能化时代,集成了边缘算力的智能模组正在逐渐成为支撑边缘算力的核心形式。具身智能将边缘算力需求提升到了一个新高度,具身智能的“大脑”不仅要处理视觉信息、生成提示词,更要负责输出指令来执行机械动作,例如特斯拉针对人形机器人开发了DOJOD1芯片,充沛的算力(362TFLPOS@FP8)驱动Optimus机器人流畅地执行各种任务。因此我们认为,在移动芯片无法满足所需算力的场景下,边缘IDC将是算力的有效补充措施。
此外,通信能力也是决定机器人能力的核心。具身智能的通信强调低时延、多连接、连续性能力,例如自动驾驶汽车上,L4级别需要带宽100Mbps,时延5-10ms。具身智能未来也有望进化成结构复杂、体型庞大或者多点分布的产品,各子模块之间需要信息融合、多维感知、协同运行,本身也会需要稳定高速的无线连接。我们认为,未来具身智能将会越来越强调边缘通信能力与边缘算力的匹配和耦合,而两者结合的较佳形式,算力模组,将有望成为具身智能的“大脑”。
5.3物联网:复苏与扩张共振
伴随万物互联的趋势进一步加速,海内外物联网行业发展稳步进行,连接数持续增加。物联网是万物数字化的首要基础,更是后续智能化、算力化的必备条件,物联网从产业链角度来看可以分成四大级别,从基础的设备层到网络层、平台层、应用层不断升级,设备层包括了物联网模组和基础的传感器等零部件,智能终端首先需要具备联网的通讯模组才能截图物联网系统,因此模组与连接数/智能终端存在一比一甚至多比一的关系,因此从连接数来看,能够大概反映出物联网行业整体景气度,经历过前几年的低谷期,目前连接数逐步提高,物联网行业景气度逐步攀升。
从国内看-物联网用户绝对数稳步提升:2023年是《物联网新型基础设施建设三年行动计划(2021—2023年)》的收盘之年,据工信部统计,最新数据截至2023年11月末,三大运营商蜂窝物联网终端用户达到23.12亿户,比上年末净增46772万户,占移动网终端连接数的比重达57.3%。
从全球看-物联网连接数继续维持稳步提升态势:根据IoTAnalytics,2022年全球物联网连接数量增长18%,达到143亿个活跃物联网端点,预测到2023年,全球联网IoT设备数量将再增长16%,达到167亿个活动端点,增速略有下降但是设备连接数依旧保持增长态势。
物联网按照通信方式可以分为wifi\蓝牙\蜂窝三大类,蜂窝物联网领域中国移动占据首要份额,对应产业链空间较大且稳定,下游供应链值得重视。根据IoTAnalytics,Wi-Fi占所有物联网连接的31%。到2022年,全球出货的支持Wi-Fi的设备中有一半以上基于最新的Wi-Fi6和Wi-Fi6E技术,主要应用在智能家居、建筑和医疗保健等领域;全球27%的物联网连接依赖蓝牙连接,设备能够在消耗有限的功耗的同时保持可靠的连接;蜂窝物联网(2G、3G、4G、5G、LTE-M和NB-IoT)目前占全球物联网连接的近20%,2022年全球蜂窝物联网连接同比增长27%,远远超过全球物联网连接的增长率,主要得益于2G和3G等旧技术的逐步淘汰,2023年,排名前五的网络运营商(中国移动、中国电信、中国联通、沃达丰和ATT)占据全球84%的蜂窝物联网连接,从物联网收入来看,前五名网络运营商占据了物联网网络运营商市场的64%,其中中国移动、ATT、德国电信(包括T-Mobile)、中国联通和Verizon领先市场。
物联网下游应用具有碎片化和长尾化的特征,其中智能汽车、笔记本电脑、网关CPE等相对的大颗粒市场,均呈现良好的复苏趋势。物联网涉及多种行业,构成其下游碎片化特征的重要原因之一,此外物联网单品众多但是出货量均难以形成大规模效应,如自动售货机、监控设备、智能城市设备如智能井盖/智能路灯等等。在各个下游应用场景中,具备部分定制化需求的场景逐步形成较大规模的出货,成为物联网中大颗粒场景,如智能汽车联网需求、笔记本电脑联网模块需求、网关/FWA/CPE需求等。在经历过去两年的原材料紧缺、库存积累、全球经济承压后,几个大颗粒市场复苏迹象较为明显。
智能汽车:自动驾驶、智能驾驶需求逐步落地,5G渗透率逐步提升。在智能汽车中物联网产品主要是指前装T-Box,作用是整车的通讯接头,目前4GT-Box渗透率较高,5G渗透率尚存在较大空间,伴随5G制式迭代升级加速、智能/自动驾驶OTA的升级需求不断提速,车载T-BOX装置率尤其是5G的渗透率逐步提升。在乘用车市场,根据高工智能汽车研究院监测数据显示,2023年1-10月中国市场乘用车车联网前装标配1301.24万辆,同比增长23.69%,标配搭载率77.78%;其中,前装标配5G车联网交付上险131.99万辆,同比增长245.61%;但5G前装搭载率仍不到10%(为7.89%)。基于目前国内5G发展整体略快于海外,我们认为,5G车载T-BOX有望率先在国内迎来规模出货,移远通信、广和通、美格智能等模组厂商均积极部署5G车载模组,在国内还细分为数传模组和自带SOC芯片的智能模组,有望率先把握5G机遇;展望海外,4G车载前装在稳步推进中。
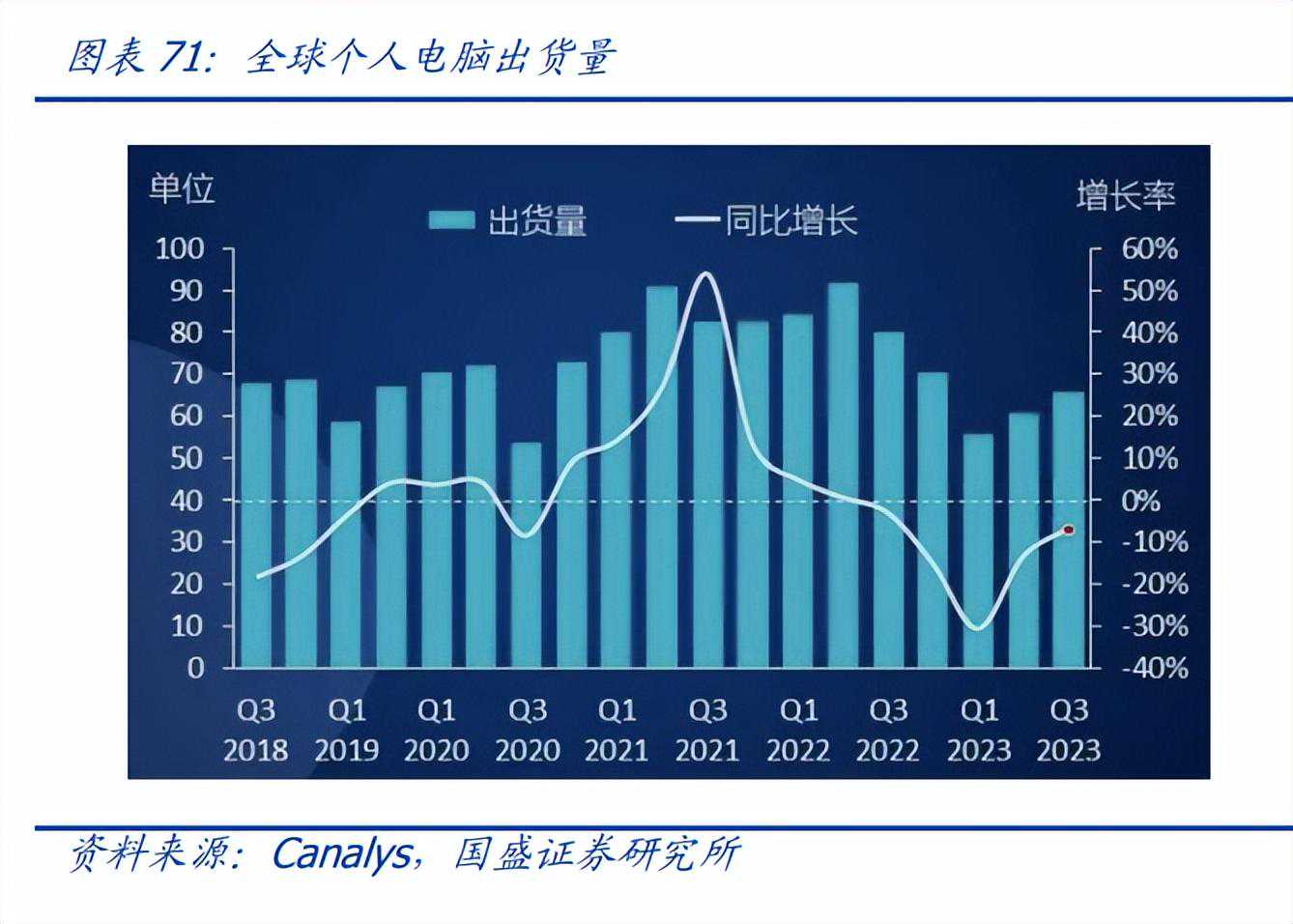
笔记本电脑:出货量下滑趋势缓解,内置蜂窝模组渗透率逐步提高。在笔记本电脑中的物联网产品主要体现为PC联网模块,按照制式主要区分为4G和5G,其中4G部分又可以进一步细分为CAT9/12/16等不同级别,笔记本联网的细分市场主要在于商务本。前两年受制于整体消费电子的低迷和累计电脑库存难以消化,笔记本联网模组也经历了低谷期,但伴随2023年逐步接近笔记本电脑新一轮的换机潮,叠加商务本的联网渗透率稳步提升,PC侧模组出货的回暖趋势较为显著。根据Canalys数据,2023年第三季度,全球个人电脑市场继续回升,总出货量为6560万台,同比下滑7%,但较二季度,回升了8%,出货量创下近一年内的最低跌幅,进一步体现了库存水平的恢复和相关需求的反弹。据StrategyAnalytics统计,2021年全球5G移动PC渗透率为蜂窝笔电的5%,约60万台,2022年上涨至8%,约100万台;StrategyAnalytics预计,2025年蜂窝笔电全球出货量将达到1430万台,其中支持5G占比将增长至65%,即增长至929.5万台。
网关/CPE/FWA:海外5G加速落地带动模块市场新机遇。FWA是一种无线接入技术,通常用于提供固定位置的宽带互联网接入服务,其方式与标准固定线路连接中使用的调制解调器和路由器类似;国内光纤光缆较为成熟因此较少用到FWA业务,主要使用群体是海外客户为主,FWA网关的直接客户以海外运营商为主,北美是全球固定无线接入市场占比较大的地区,在固定无线宽带技术的投资较多。目前海外正在经历4G加速切换到5G的通信产业制式升级周期,借助FWA将5G完成最后一英里的连接,可以消除部署和维护物理线路相关的成本和时间延迟;而且此前4GFWA在使用体验中由于速度和可靠性不够快,不足以替代固网宽带的需求,随着5G带来的速度提升,5GFWA有望成为移动宽带和标准固定线路连接之间的汇聚点。根据statista预测,到2026年,预计5GFWA连接数将达到7182万个,到2030年,5GFWA可能占所有连接数的21%。
(本文仅供参考,不代表我们的任何投资建议。如需使用相关信息,请参阅报告原文。)

-
 2025-08-30
2025-08-30 -
 2025-10-11
2025-10-11 -

百万元级HIFI音响频现,2016广州国际音箱唱片展精彩回顾
2025-01-16 -
 2025-09-20
2025-09-20
-
新能源车不保值?买二手更划算!
2025-03-24 -
m32/x32调音台#线阵音响
2024-11-20 -
历史最久中国音响展全回顾:多套顶级音响身价不输保时捷与法拉利
2024-11-23 -
厦门这些好单位正在招人!编内编外都有!了解一下~
2025-10-09