
作者|李秋键
责编|Carol
人工智能作为当前热门在我们生活中得到了广泛应用,尤其是在智能游戏方面,有的已经达到了可以和职业选手匹敌的效果。而DQN算法作为智能游戏的经典选择算法,其主要是通过奖励惩罚机制来迭代模型,来达到更接近于人类学习的效果。
那在强化学习中,神经网络是如何被训练的呢?首先,我们需要a1,a2正确的Q值,这个Q值我们就用之前在Qlearning中的Q现实来代替.同样我们还需要一个Q估计来实现神经网络的更新.所以神经网络的的参数就是老的NN参数加学习率alpha乘以Q现实和Q估计的差距。
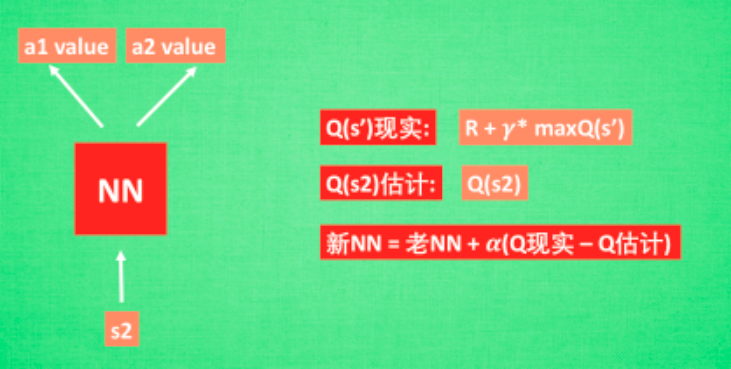
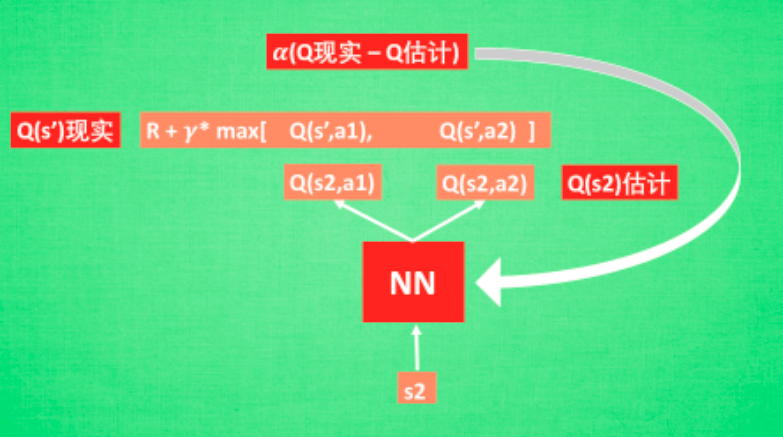
我们通过NN预测出Q(s2,a1)和Q(s2,a2)的值,这就是Q估计.然后我们选取Q估计中最大值的动作来换取环境中的奖励reward.而Q现实中也包含从神经网络分析出来的两个Q估计值,不过这个Q估计是针对于下一步在s’的估计.最后再通过刚刚所说的算法更新神经网络中的参数.
DQN是第一个将深度学习模型与强化学习结合在一起从而成功地直接从高维的输入学习控制策略。
创新点:
基于Q-Learning构造LossFunction(不算很新,过往使用线性和非线性函数拟合Q-Table时就是这样做)。
通过experiencereplay(经验池)解决相关性及非静态分布问题;
使用TargetNet解决稳定性问题。
优点:
算法通用性,可玩不同游戏;
-to-训练方式;
可生产大量样本供监督学习。
缺点:
无法应用于连续动作控制;
只能处理只需短时记忆问题,无法处理需长时记忆问题(后续研究提出了使用LSTM等改进方法);
CNN不一定收敛,需精良调参。
整体的程序效果如下:

实验前的准备
首先我们使用的python版本是3.6.5所用到的库有cv2库用来图像处理;
Numpy库用来矩阵运算;TensorFlow框架用来训练和加载模型。Collection库用于高性能的数据结构。

程序的搭建
1、游戏结构设定:
我们在DQN训练前需要有自己设定好的程序,即在这里为弹珠游戏。在游戏整体框架搭建完成后,对于计算机的决策方式我们需要给他一个初始化的决策算法为了达到更快的训练效果。
程序结构的部分代码如下:
def__init__(self):self.__initGame更新ball的位置_pos=_pos[0]+[0],_pos[1]+[1]image=image[321:,:]=Falseifmax(_1_score,_2_score)=20:_1_score=0_2_score=0terminal=Truereturnimage,reward,terminaldefupdate_frame(self,action):assertlen(action)==3=0行动paddle_1(训练对象)ifaction[0]==1:_1_speed=0elifaction[1]==1:_1_speed=-[2]==1:_1_speed=_1_pos=_1_pos[0],max(min(_1_speed+_1_pos[1],420),10)
接着设置一个简单的初始化决策。根据结果判断奖励和惩罚机制,即球撞到拍上奖励,撞到墙上等等惩罚:
其中代码如下:
行动ball拍未接到球(另外一个拍得分)_pos[0]5.:_2_score+=1reward=___pos[0]620.:_1_score+=1reward=__reset计算lossloss=_loss(q_values_ph,action_now_ph,target_q_values_ph)游戏gameState=PongGame当前的动作action_now=(_action)action_now[0]=1读取和保存checkpointsaver=(_variables_initializer)checkpoint=_checkpoint_state()_checkpoint_path:(session,_checkpoint_path)print('[INFO]:Load%ssuccessfully'%_checkpoint_path)else:print('[INFO]:Noweightsfound,starttotrainanewmodel')prob=_probnum_frame=0logF=open(,'a')whileTrue:q_values=q_values_(feed_dict={x:[scene_now]})action_idx=get_action_idx(q_values=q_values,prob=prob,num_frame=num_frame,OBSERVE=,num_action=_action)action_now=(_action)action_now[action_idx]=1prob=down_prob(prob=prob,num_frame=num_frame,OBSERVE=,EXPLORE=,init_prob=_prob,_prob=_prob)for_inrange(_interval):scene_next,reward,terminal=_frame(action_now=action_now,scene_now=scene_now,gameState=gameState)scene_now=scene_((scene_now,action_now,reward,scene_next,terminal))iflen(dataDeque)_MEMORY:_now=Noneif(num_):minibatch=(dataDeque,_size)scene_now_batch=[mb[0]formbinminibatch]action_batch=[mb[1]formbinminibatch]reward_batch=[mb[2]formbinminibatch]scene_next_batch=[mb[3]formbinminibatch]q_values_batch=q_values_(feed_dict={x:scene_next_batch})target_q_values=_target_q_values(reward_batch,q_values_batch,minibatch)(feed_dict={target_q_values_ph:target_q_values,action_now_ph:action_batch,x:scene_now_batch})loss_now=(loss,feed_dict={target_q_values_ph:target_q_values,action_now_ph:action_batch,x:scene_now_batch})num_frame+=1ifnum_frame%_interval==0:name='DQN_Pong'(session,(,name),global_step=num_frame)log_content='Frame:%s,Prob:%s,Action:%s,Reward:%s,Q_max:%s,Loss:%s'%(str(num_frame),str(prob),str(action_idx),str(reward),str((q_values)),str(loss_now))(log_content+'\n')print(log_content)'''创建网络'''defcreate_network(self):'''W_conv1=_weight_variable([9,9,4,16])b_conv1=_bias_variable([16])W_conv2=_weight_variable([7,7,16,32])b_conv2=_bias_variable([32])W_conv3=_weight_variable([5,5,32,32])b_conv3=_bias_variable([32])W_conv4=_weight_variable([5,5,32,64])b_conv4=_bias_variable([64])W_conv5=_weight_variable([3,3,64,64])b_conv5=_bias_variable([64])'''W_conv1=_weight_variable([8,8,4,32])b_conv1=_bias_variable([32])W_conv2=_weight_variable([4,4,32,64])b_conv2=_bias_variable([64])W_conv3=_weight_variable([3,3,64,64])b_conv3=_bias_variable([64])inputplaceholderx=('float',[None,80,80,4])'''conv1=(_normalization((x,W_conv1,4)+b_conv1,training=_train,momentum=0.9))conv2=(_normalization((conv1,W_conv2,2)+b_conv2,training=_train,momentum=0.9))conv3=(_normalization((conv2,W_conv3,2)+b_conv3,training=_train,momentum=0.9))conv4=(_normalization((conv3,W_conv4,1)+b_conv4,training=_train,momentum=0.9))conv5=(_normalization((conv4,W_conv5,1)+b_conv5,training=_train,momentum=0.9))flatten=(conv5,[-1,1600])'''conv1=((x,W_conv1,4)+b_conv1)pool1=(conv1)conv2=((pool1,W_conv2,2)+b_conv2)conv3=((conv2,W_conv3,1)+b_conv3)flatten=(conv3,[-1,1600])fc1=(_normalization((flatten,W_fc1)+b_fc1,training=_train,momentum=0.9))fc2=(fc1,W_fc2)+b_fc2returnx,fc2到这里,我们整体的程序就搭建完成,下面为我们程序的运行结果:
源码地址:
提取码:p74p

-
 2026-01-09
2026-01-09 -
 2026-01-14
2026-01-14 -

P15半自动打包机——ZD-16全自动打包机实际操作对比区别
2025-02-01 -

你网购过这13批次电子类商品吗?抽检不合格~涉及标称PHILIPS、ROMOSS等
2025-10-16
-
功放和音响的区别
2024-11-22 -
美式豪华 凯迪拉克CT5-V 暴力绅士
2025-08-17 -
环球网评:美国公然为“东伊运”张目是在开历史倒车
2026-01-26 -
平行时空音乐嘉年华 本周末午夜狂欢即将来临
2025-11-06